定义
矩阵奇异值分解(Singular Value Decomposition,SVD )是指将一个非零的m × n m \times n m × n A A A A ∈ R m × n A \in R^{m \times n} A ∈ R m × n
A = U Σ V T \begin{align}
A = U \Sigma V^T
\end{align}
A = U Σ V T
其中,U U U m m m orthogonal matrix ),V V V n n n Σ \Sigma Σ m × n m \times n m × n rectangular diagonal matrix ) , 满足
U U T = I V V T = I Σ = d i a g ( σ 1 . σ 2 , . . . , σ p ) σ 1 ≥ σ 2 ≥ . . . ≥ σ p ≥ 0 p = m i n ( m , n ) \begin{array}{c}
UU^T = I\\
VV^T = I\\
\Sigma = diag(\sigma_1 . \sigma_2 , ... , \sigma_p)\\
\sigma_1 \ge \sigma_2 \ge ... \ge \sigma_p \ge 0 \\
p = min(m,n)
\end{array}
U U T = I V V T = I Σ = d ia g ( σ 1 . σ 2 , ... , σ p ) σ 1 ≥ σ 2 ≥ ... ≥ σ p ≥ 0 p = min ( m , n )
U Σ V T U\Sigma V^T U Σ V T A A A σ i \sigma_i σ i A A A U U U V V V
奇异值分解基本定理
若A A A m × n m \times n m × n A ∈ R m × n A\in R^{m \times n} A ∈ R m × n A A A
A = U Σ V T \begin{align}
A = U \Sigma V^T
\end{align}
A = U Σ V T
其中,U U U m m m V V V n n n Σ \Sigma Σ m × n m \times n m × n
提示Introduction to Linear Algebra(Fifth Edition)第371页,或李航的 机器学习方法 第231页。
紧奇异值分解与截断奇异值分解
定义所给出的又称为矩阵的完全奇异值分解 (full singular value decomposition )。实际常用的是奇异值分解的紧凑形式与截断形式。
紧奇异值分解定义
设有m × n m \times n m × n A A A r a n k ( A ) = r , r ≤ m i n ( m , n ) rank(A) = r,r \le min(m,n) r ank ( A ) = r , r ≤ min ( m , n ) U r Σ r V r T U_r \Sigma_r {V_r}^T U r Σ r V r T A A A compact singular value decomposition ),即
A = U r Σ r V r T \begin{align}
A = U_r \Sigma_r {V_r}^T
\end{align}
A = U r Σ r V r T
其中,U r U_r U r m × n m\times n m × n V r V_r V r n × r n \times r n × r Σ r \Sigma_r Σ r r r r U r U_{r} U r U U U r r r V r V_{r} V r V V V r r r Σ r \Sigma_{r} Σ r Σ \Sigma Σ r r r Σ r \Sigma_{r} Σ r A A A
截断奇异值分解定义
设A A A m × n m \times n m × n r a n k ( A ) = r rank(A) = r r ank ( A ) = r 0 < k < r 0 < k < r 0 < k < r U k Σ k V k T U_{k} \Sigma_{k} V_{k}^T U k Σ k V k T A A A truncated singular value decomposition ),即
A ≈ U k Σ k V k T \begin{align}
A \approx U_{k} \Sigma_{k} V_{k}^T
\end{align}
A ≈ U k Σ k V k T
其中,U k U_{k} U k m × k m \times k m × k V k V_{k} V k n × k n \times k n × k Σ k \Sigma_{k} Σ k k k k U k U_{k} U k U U U k k k V k V_{k} V k V V V k k k Σ k \Sigma_{k} Σ k Σ \Sigma Σ k k k Σ k \Sigma_{k} Σ k A A A
几何解释
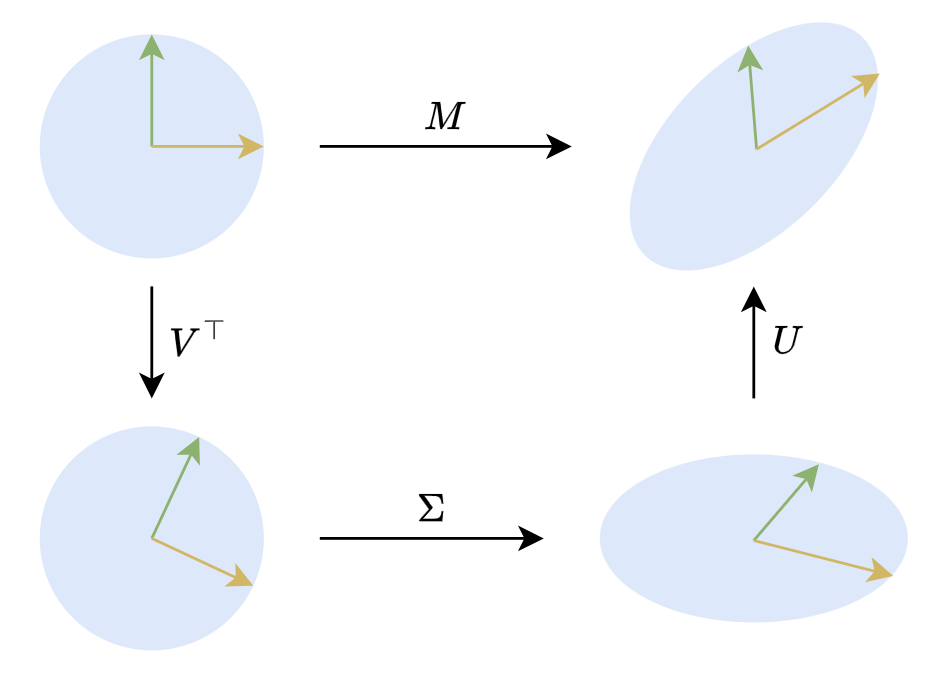
从线性变换的角度理解奇异值分解,m × n m \times n m × n A \boldsymbol{A} A n n n R n \boldsymbol{R}^{n} R n m m m R m R^{m} R m
T : x → A x T: \boldsymbol{x} \rightarrow \boldsymbol{A} \boldsymbol{x}
T : x → A x
其中, x ∈ R n x \in R^{n} x ∈ R n A x ∈ R m \boldsymbol{A x} \in \boldsymbol{R}^{m} Ax ∈ R m x \boldsymbol{x} x A x \boldsymbol{A x} Ax
对矩阵A \boldsymbol{A} A R n R^{n} R n U \boldsymbol{U} U u 1 , u 2 , ⋯ , u m \boldsymbol{u}_{1}, \boldsymbol{u}_{2}, \cdots, \boldsymbol{u}_{m} u 1 , u 2 , ⋯ , u m R m \boldsymbol{R}^{m} R m R m \boldsymbol{R}^{m} R m Σ \boldsymbol{\Sigma} Σ σ 1 , σ 2 , ⋯ , σ n \sigma_{1}, \sigma_{2}, \cdots, \sigma_{n} σ 1 , σ 2 , ⋯ , σ n R n \boldsymbol{R}^{n} R n σ 1 , σ 2 , ⋯ , σ n \sigma_{1}, \sigma_{2}, \cdots, \sigma_{n} σ 1 , σ 2 , ⋯ , σ n
对于任意一个向量x ∈ R n \boldsymbol{x} \in \boldsymbol{R}^{n} x ∈ R n A = U Σ V T \boldsymbol{A}=\boldsymbol{U} \boldsymbol{\Sigma} \boldsymbol{V}^{\mathrm{T}} A = U Σ V T V T \boldsymbol{V}^{\mathrm{T}} V T Σ \boldsymbol{\Sigma} Σ U \boldsymbol{U} U A x ∈ R m \boldsymbol{A x} \in \boldsymbol{R}^{\boldsymbol{m}} Ax ∈ R m
奇异值分解的性质
设矩阵A A A A = U Σ V T A = U \Sigma V^T A = U Σ V T
A T A = ( U Σ V T ) T ( U Σ V T ) = V ( Σ T Σ ) V T A A T = ( U Σ V T ) ( U Σ V T ) T = U ( Σ Σ T ) U T \begin{align}
A^T A = (U \Sigma V^T)^T(U \Sigma V^T) = V(\Sigma^T \Sigma)V^T \\
AA^T = (U \Sigma V^T)(U \Sigma V^T)^T = U(\Sigma \Sigma^T)U^T
\end{align}
A T A = ( U Σ V T ) T ( U Σ V T ) = V ( Σ T Σ ) V T A A T = ( U Σ V T ) ( U Σ V T ) T = U ( Σ Σ T ) U T
在矩阵A A A
由A = U Σ V T A = U \Sigma V^T A = U Σ V T
A V = U Σ \begin{array}{c}
AV = U \Sigma
\end{array}
A V = U Σ
比较这一等式两端的第j j j
A v j = σ j u j , j = 1 , 2 , ⋯ , n \begin{align}
Av_{j} = \sigma_{j} u_{j},j = 1,2,\cdots,n
\end{align}
A v j = σ j u j , j = 1 , 2 , ⋯ , n
这就是矩阵A A A
类似的,有
A T U = V Σ T \begin{array}{}
A^T U = V \Sigma^T
\end{array}
A T U = V Σ T
得到:
A T u j = σ j v j , , j = 1 , 2 , ⋯ , n A T u j = 0 , j = n + 1 , n + 2 , ⋯ , m \begin{align}
A^Tu_{j}=\sigma_{j}v_{j},,j = 1,2,\cdots,n \\
A^Tu_{j} = 0,j = n+1,n+2,\cdots,m
\end{align}
A T u j = σ j v j ,, j = 1 , 2 , ⋯ , n A T u j = 0 , j = n + 1 , n + 2 , ⋯ , m
这就是矩阵A A A
矩阵A A A σ 1 , σ 2 , ⋯ , σ n \sigma_{1},\sigma_{2},\cdots,\sigma_{n} σ 1 , σ 2 , ⋯ , σ n U U U V V V
矩阵A A A Σ \Sigma Σ σ i \sigma_{i} σ i r r r
矩阵A A A r r r v 1 , v 2 , … , v r v_{1},v_{2},\dots,v_{r} v 1 , v 2 , … , v r A T A^T A T R ( A T ) R(A^T) R ( A T ) n − r n-r n − r v r + 1 , v r + 2 , … , v n v_{r+1},v_{r+2},\dots,v_{n} v r + 1 , v r + 2 , … , v n A A A N ( A ) N(A) N ( A ) A A A r r r u 1 , u 2 , … , u r u_{1},u_{2},\dots,u_{r} u 1 , u 2 , … , u r A A A R ( A ) R(A) R ( A ) A A A n − r n-r n − r u r + 1 , u r + 2 , … , u n u_{r+1},u_{r+2},\dots,u_{n} u r + 1 , u r + 2 , … , u n A T A^T A T N ( A T ) N(A^T) N ( A T ) 这里的性质完美的符合了Gilbert Strang的那副经典图片。
计算方法
求A T A A^TA A T A
求n n n V V V
求m × n m \times n m × n Σ \Sigma Σ
求m m m U U U
奇异值分解与矩阵近似
弗罗贝尼乌斯范数
奇异值分解也是一种矩阵近似的方法,这个近似是在弗罗贝尼乌斯范数(Frobenius norm )意义下的近似。矩阵的弗罗贝尼乌斯范数是向量L 2 L_{2} L 2
弗罗贝尼乌斯范数的定义
设矩阵A ∈ R m × n A \in R^{m \times n} A ∈ R m × n A = [ a i j ] m × n A = [a_{ij}]_{m \times n} A = [ a ij ] m × n A A A
∥ A ∥ F = ( ∑ i = 1 m ∑ j = 1 n a i j 2 ) 1 2 \begin{align}
\Vert A \Vert_{F} = \left( \sum_{i=1}^{m} \sum_{j=1}^{n} a_{ij}^2 \right)^{\frac{1}{2}}
\end{align}
∥ A ∥ F = ( i = 1 ∑ m j = 1 ∑ n a ij 2 ) 2 1
引理
设矩阵A ∈ R m × n A \in R^{m \times n} A ∈ R m × n A A A U Σ V T U \Sigma V^T U Σ V T Σ = d i a g ( σ 1 , σ 2 , ⋯ , σ n ) \Sigma = diag(\sigma_{1},\sigma_{2},\cdots,\sigma_{n}) Σ = d ia g ( σ 1 , σ 2 , ⋯ , σ n )
∥ A ∥ F = ( σ 1 2 + σ 2 2 + ⋯ + σ n 2 ) \begin{align}
\Vert A \Vert_{F} = (\sigma_{1}^2+\sigma_{2}^2+\cdots+\sigma_{n}^2)
\end{align}
∥ A ∥ F = ( σ 1 2 + σ 2 2 + ⋯ + σ n 2 )
矩阵的最优近似
奇异值分解是在平方损失(弗罗贝尼乌斯范数)意义下对矩阵的最优近似,即数据压缩。
定理 设矩阵A ∈ R m × n A \in R^{m \times n} A ∈ R m × n r a n k ( A ) = r rank(A) = r r ank ( A ) = r M \mathcal{M} M R m × n R^{m \times n} R m × n k k k 0 < k < r 0 <k < r 0 < k < r k k k X ∈ M X \in \mathcal{M} X ∈ M
∥ A − X ∥ F = min S ∈ M ∥ A − S ∥ F \begin{align}
\Vert A - X \Vert_{F} = \min_{S \in \mathcal{M}} \Vert A - S \Vert_{F}
\end{align}
∥ A − X ∥ F = S ∈ M min ∥ A − S ∥ F
称矩阵X X X A A A
定理 设矩阵A ∈ R m × n \boldsymbol{A} \in \boldsymbol{R}^{m \times n} A ∈ R m × n rank ( A ) = r \operatorname{rank}(\boldsymbol{A})=r rank ( A ) = r A = U Σ V T \boldsymbol{A}=\boldsymbol{U} \boldsymbol{\Sigma} \boldsymbol{V}^{\mathrm{T}} A = U Σ V T M \mathcal{M} M R m × n \boldsymbol{R}^{m \times n} R m × n k k k 0 < k < r 0<k<r 0 < k < r k k k X ∈ M \boldsymbol{X} \in \mathcal{M} X ∈ M
∥ A − X ∥ F = min S ∈ M ∥ A − S ∥ F \begin{align}
\|\boldsymbol{A}-\boldsymbol{X}\|_{F}=\min _{S \in \mathcal{M}}\|\boldsymbol{A}-\boldsymbol{S}\|_{F}
\end{align}
∥ A − X ∥ F = S ∈ M min ∥ A − S ∥ F
则
∥ A − X ∥ F = ( σ k + 1 2 + σ k + 2 2 + ⋯ + σ n 2 ) 1 2 \begin{align}
\|\boldsymbol{A}-\boldsymbol{X}\|_{F}=\left(\sigma_{k+1}^{2}+\sigma_{k+2}^{2}+\cdots+\sigma_{n}^{2}\right)^{\frac{1}{2}}
\end{align}
∥ A − X ∥ F = ( σ k + 1 2 + σ k + 2 2 + ⋯ + σ n 2 ) 2 1
特别地, 若 A ′ = U Σ ′ V T \boldsymbol{A}^{\prime}=\boldsymbol{U} \boldsymbol{\Sigma}^{\prime} \boldsymbol{V}^{\mathrm{T}} A ′ = U Σ ′ V T
Σ ′ = [ σ 1 ⋱ 0 σ k 0 0 ⋱ 0 ] = [ Σ k 0 o 0 ] \boldsymbol{\Sigma}^{\prime}=\left[\begin{array}{cccccc}
\sigma_{1} & & & & & \\
& \ddots & & & 0 & \\
& & \sigma_{k} & & & \\
& & & 0 & & \\
& 0 & & & \ddots & \\
& & & & & 0
\end{array}\right]=\left[\begin{array}{cc}
\Sigma_{k} & 0 \\
o & 0
\end{array}\right]
Σ ′ = σ 1 ⋱ 0 σ k 0 0 ⋱ 0 = [ Σ k o 0 0 ]
则
∥ A − A ′ ∥ F = ( σ k + 1 2 + σ k + 2 2 + ⋯ + σ n 2 ) 1 2 = min S ∈ M ∥ A − S ∥ F \begin{align}
\left\|\boldsymbol{A}-\boldsymbol{A}^{\prime}\right\|_{F}=\left(\sigma_{k+1}^{2}+\sigma_{k+2}^{2}+\cdots+\sigma_{n}^{2}\right)^{\frac{1}{2}}=\min _{S \in \mathcal{M}}\|\boldsymbol{A}-\boldsymbol{S}\|_{F}
\end{align}
A − A ′ F = ( σ k + 1 2 + σ k + 2 2 + ⋯ + σ n 2 ) 2 1 = S ∈ M min ∥ A − S ∥ F
矩阵的外积展开式
A = σ 1 u 1 v 1 T + σ 2 u 2 v 2 T + ⋯ + σ n u n v n T = ∑ k = 1 n A k = ∑ k = 1 n σ k u k v k T \begin{align}
A &= \sigma_{1}u_{1}v_{1}^T + \sigma_{2}u_{2}v_{2}^T + \cdots + \sigma_{n}u_{n}v_{n}^T\\
&= \sum_{k=1}^nA_{k}=\sum_{k=1}^n\sigma_{k}u_{k}v_{k}^T\\
\end{align}
A = σ 1 u 1 v 1 T + σ 2 u 2 v 2 T + ⋯ + σ n u n v n T = k = 1 ∑ n A k = k = 1 ∑ n σ k u k v k T
若A A A n n n
A = σ 1 u 1 v 1 T + σ 2 u 2 v 2 T + ⋯ + σ n u n v n T \begin{align}
A = \sigma_{1}u_{1}v_{1}^T + \sigma_{2}u_{2}v_{2}^T + \cdots + \sigma_{n}u_{n}v_{n}^T
\end{align}
A = σ 1 u 1 v 1 T + σ 2 u 2 v 2 T + ⋯ + σ n u n v n T
Rayleigh quotient 瑞利商
定义
本文采用STRANG G.Introduction to Linear Algebra 的定义:
r ( x ) = x T S x x T x \begin{align}
r(x) = \frac{x^T S x}{x^T x}
\end{align}
r ( x ) = x T x x T S x
习题
1.随机矩阵理论σ 1 \sigma_{1} σ 1 σ 20 \sigma_{20} σ 20 σ \sigma σ Introduction to Linear Algebra P370)
该题代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 A = rand (20 , 40 ); B = randn (20 , 40 ); s_A = svd(A); s_B = svd(B); figure ;subplot(1 ,2 ,1 ); plot (1 :20 , s_A, 'b-o' , 'LineWidth' , 1.5 );title('Singular Values of A (rand)' ); xlabel('Index' ); ylabel('\sigma_i' ); grid on; subplot(1 ,2 ,2 ); plot (1 :20 , s_B, 'r-*' , 'LineWidth' , 1.5 );title('Singular Values of B (randn)' ); xlabel('Index' ); ylabel('\sigma_i' ); grid on;
观察σ i − I n d e x \sigma_{i}-Index σ i − I n d e x