前情提要:DL#1.1 感知机 | TheValuePoint’s Blog
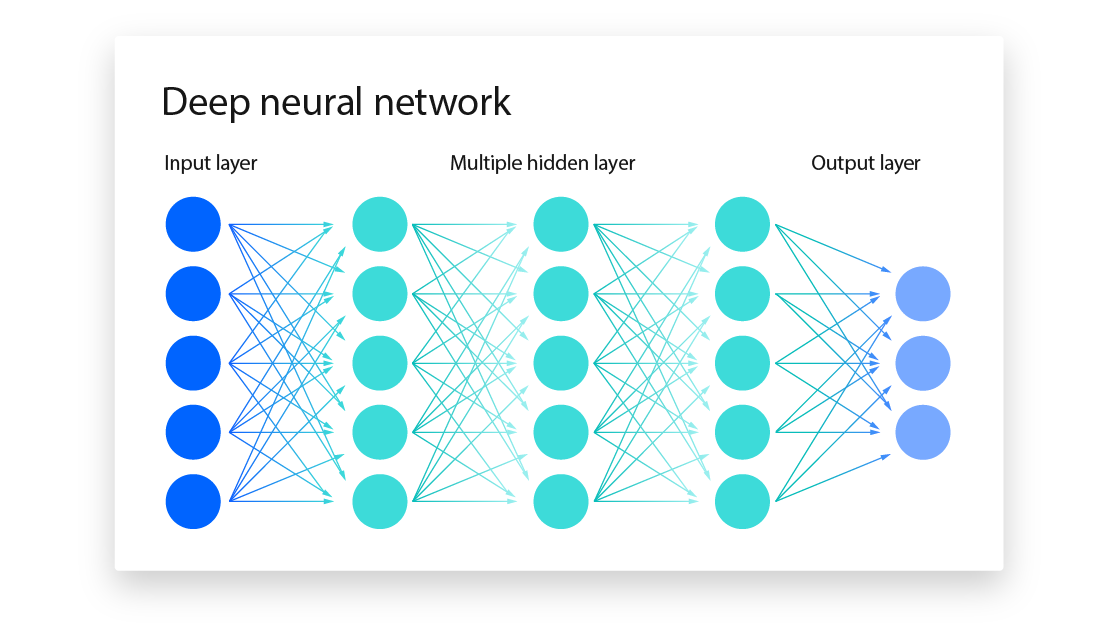
深度前馈网络(Deep feedforward networks),也称前馈神经网络(feedforward neural networks)或多层感知机(multilayer perceptrons, MLPs),是典型的深度学习模型。前馈网络的目标是近似某个函数 f∗。例如,对于分类器而言,y=f∗(x) 将输入 x 映射到一个类别 y。前馈网络通过定义映射关系 y=f(x;θ),并学习使得函数逼近最优的参数值 θ,从而获得最佳的函数逼近效果。
这类模型之所以称为“前馈”,是因为信息从输入 x 开始,经过定义 f 所需的中间计算过程(即隐藏层的层级变换),最终单向流向输出 y。在整个过程中,模型的输出不会通过反馈连接重新注入网络自身,这种单向传播特性是区分前馈网络与循环神经网络的核心特征。
前馈神经网络之所以被称为"网络",是因为它们通常通过组合多个不同函数来表征。该模型与描述函数组合方式的有向无环图(directed acyclic graph)相关联。例如,由三个函数f(1)、f(2)和f(3)构成的链式结构可表示为f(x)=f(3)(f(2)(f(1)(x)))。这类链式结构是神经网络最常用的架构形式。在此结构中,f(1)称为网络的第一层,f(2)称为第二层,依此类推。链式结构的整体长度决定了模型的深度,"深度学习"这一术语正是源于此命名规则。
前馈网络的最后一层称为输出层。在神经网络训练过程中,我们通过调整参数使得f(x)逼近f∗(x)。训练数据提供了f∗(x)在不同训练点上的含噪近似样本,每个样本x都带有标签y≈f∗(x)。训练样本直接规定了输出层在每个x处必须执行的操作:必须生成与y相近的值。其他层的行为并不直接由训练数据指定——学习算法需要自主决定如何利用这些中间层来实现期望的输出,但训练数据并未说明每个单独层应当执行何种具体操作。由于训练数据未展示这些中间层的期望输出,故将其称为隐藏层。
深度前馈网络之所以被称为“神经”网络,是因为其设计受到神经科学的启发。网络的每个隐藏层通常是向量值的,这些隐藏层的维度决定了模型的宽度。向量中的每个元素可类比为神经元的角色。我们不仅可以将层视为一个向量到向量的函数,也可以将其视为由多个并行作用的单元构成——每个单元表示一个向量到标量的函数。每个单元类似于神经元:接收来自其他多个单元的输入,并计算其自身的激活值。使用多层向量值表示的思想源于神经科学,而用于计算这些表示的函数f(i)(x)的选择,也部分参考了生物神经元功能的神经科学观察。然而,现代神经网络的研究更多受到数学和工程学科的指导,其目标并非精确模拟大脑。前馈网络应被视为为实现统计泛化而设计的函数逼近机器,偶尔从大脑的认知中汲取灵感,而非对大脑功能的直接建模。
诱导局部场
在神经网络中,诱导局部场(induced local field)是神经元在激活函数处理前的净输入信号,其数学定义为:
vj(l)(n)=i∑wji(l)(n)yi(l−1)(n)
其中, yi(l−1)(n)为前一层(l−1层)神经元i在时刻n的输出,wji(l)(n)为连接l−1层神经元i → l层神经元j的突触权重。
前馈神经网络学习的优化算法
前馈神经网络学习变成给定网络架构 f(x;θ),训练数据集 T 的条件下,最小化目标函数 L(θ)(通常定义为训练集上所有样本损失的平均或总和),得到最优参数 θ^ 的优化问题(最小化问题)。
θ^=argθminL(θ)=argθminN1i=1∑NL(f(xi;θ),yi)
前馈神经网络学习的目标函数一般是非凸函数,优化问题是非凸优化。从前馈神经网络的等价性可以得知,一个神经网络通常有大量等价的参数向量,所以其学习的优化问题有大量等价的局部最优点(最小点)。
深度学习包括前馈神经网络学习,均使用迭代优化算法,包括梯度下降法和随机梯度下降法,后者则更为常用。具体参考:
反向传播算法
反向传播(Back-Propagation,backprop)算法是优化人工神经网络的关键机器学习技术。它通过梯度下降算法实现网络权重的更新,这一机制构成了现代人工智能深度学习模型实现"学习"功能的核心基础。
作为“误差反向传播”(Backward Propagation of Error)的简称,该技术提供了一种精妙的数学方法,能够精确计算神经网络中任意权重或偏置参数的调整对模型预测精度的影响。这项技术是监督学习、半监督学习和自监督学习训练神经网络的基石。
反向传播的数学逻辑建立在人工神经网络层级结构的本质特征之上:神经网络的各层神经元实质上构成了一系列嵌套数学函数。在训练过程中,这些相互关联的数学表达式被进一步嵌套至另一个关键函数——“损失函数”(loss function)。该函数通过量化给定输入下神经网络实际输出与期望输出(即"真实值")之间的差异(即"损失")来评估模型性能。
基于这一数学架构,我们可以运用源于17世纪的微积分基本原理——链式法则(Chain Rule),逐层计算每个神经元(neuron)对总体损失(loss)的贡献率。通过这种数学操作,能够精确量化神经网络方程中任意变量(即权重或偏置参数)调整所产生的影响。
从数学视角来看,反向传播通过从输出层(Output Layer)向输入层(Input Layer)的逆向运算,高效计算出损失函数的梯度——即网络中各层方程的导数向量。这个梯度向量为“梯度下降”等优化算法提供了关键信息:它不仅指示需要调整的数学方程,还明确了参数调整的最优方向以降低损失值。
这三个相互关联的运算过程——通过损失函数追踪不同输入下的模型误差、反向传播误差以分析网络各组件对误差的贡献度、以及基于梯度信息调整模型参数的优化算法——共同构成了深度学习模型的学习机制。因此,从基础的多层感知机到生成式AI所采用的复杂深度神经网络架构,反向传播始终是神经网络模型训练的基础性技术。
反向传播的直观理解
反向传播算法实际上就是链式求导,就是如同剥洋葱那样从外到内一层一层地求导,降梯度。
首先,连接神经元i到神经元j的突触权重修正量Δwji(n)由δ规则定义:
(权重修正量Δwji(n))=(学习率参数η)×(局部梯度δj(n))×(神经元j的输入信号yi(n))
其次,局部梯度δj(n)取决于神经元j是输出节点还是隐藏节点:
- 若神经元j是输出节点:δj(n)等于神经元j的激励函数导数φj′(vj(n))与其误差信号ej(n)的乘积。
- 若神经元j是隐藏节点:δj(n)等于相关导数φj′(vj(n))与下一层(隐藏层或输出层)中连接到神经元j的所有神经元的δ加权和的乘积。
计算图
为了更精确地描述反向传播算法,使用更精确的计算图(Computation Graph)语言是很有帮助的。计算图是表示函数计算过程的有向无环图,其结点表示变量,有向边表示变量(输入变量和输出变量)之间的函数依存关系。每一个非起点的结点对应一个基本函数,如加减乘除运算。图整体对应的是由基本函数组成的复合函数。计算图上的计算有正向传播和反向传播。
如下图所示,可得
∂w∂z=∂y∂z∂x∂y∂w∂x

信号流图与神经网络
信号与系统最有用的一集.jpg
1.初始化。假设没有任何先验信息可用,从均匀分布中选取突触权重和阈值,该分布的均值为零,其方差的选择应使得神经元诱导局部场的标准差位于S型激活函数线性部分与标准部分的过渡区域。
2.训练样本的呈现。向网络提供一轮训练样本。对于样本中的每个示例(按某种顺序排列),分别执行第3点和第4点描述的前向计算和反向计算序列。
3.前向计算。设周期中的一个训练示例为(x(n),d(n)),其中输入向量x(n)应用于输入层的感知节点,期望响应向量d(n)呈现给输出层的计算节点。通过逐层前向传播计算网络的诱导局部场和功能信号。对于层l中神经元j的诱导局部场vj(l)(n),计算公式为:
vj(l)(n)=t∑wji(l)(n)yi(l−1)(n)
yi(l−1)(n)是前一层l−1中神经元i在迭代n时的输出(功能)信号,wji(l)(n)是层l中神经元j从层l−1中神经元i接收的突触权重。
当i=0时,y0(l−1)(n)=+1,且wj0(l)(n)=bj(l)(n)是层l中神经元j的偏置。
若使用S型激活函数,层l中神经元j的输出信号为:
yj(l)=φj(vj(n))
若神经元j位于第一个隐藏层(即l=1),则:
yj(0)(n)=xj(n)
其中xj(n)是输入向量x(n)的第j个元素。
若神经元j位于输出层(即l=L,L为网络深度),则:
yj(L)=oj(n)
误差信号的计算公式为:
ej(n)=dj(n)−oj(n)
其中dj(n)是期望响应向量d(n)的第j个元素。
4.反向计算。计算网络的局部梯度δ(即δ值),定义如下:
δj(l)(n)={ej(L)(n)φj′(vj(L)(n))φj′(vj(l)(n))∑kδk(l+1)(n)wkj(l+1)(n)对于输出层L中的神经元j对于隐藏层l中的神经元j
其中φj′(⋅)表示对自变量的导数。根据广义增量规则调整层l的突触权重:
wji(l)(n+1)=wji(l)(n)+α[Δwji(l)(n−1)]+ηδj(l)(n)yi(l−1)(n)
其中η为学习率参数,α为动量常数。
5.迭代。通过向网络呈现新的训练周期,迭代执行第3点和第4点中的前向和反向计算,直到满足停止条件。
注意:训练样本的呈现顺序应在每个周期中随机打乱。动量和学习率参数通常随着训练迭代次数的增加而调整(通常是减小)。

