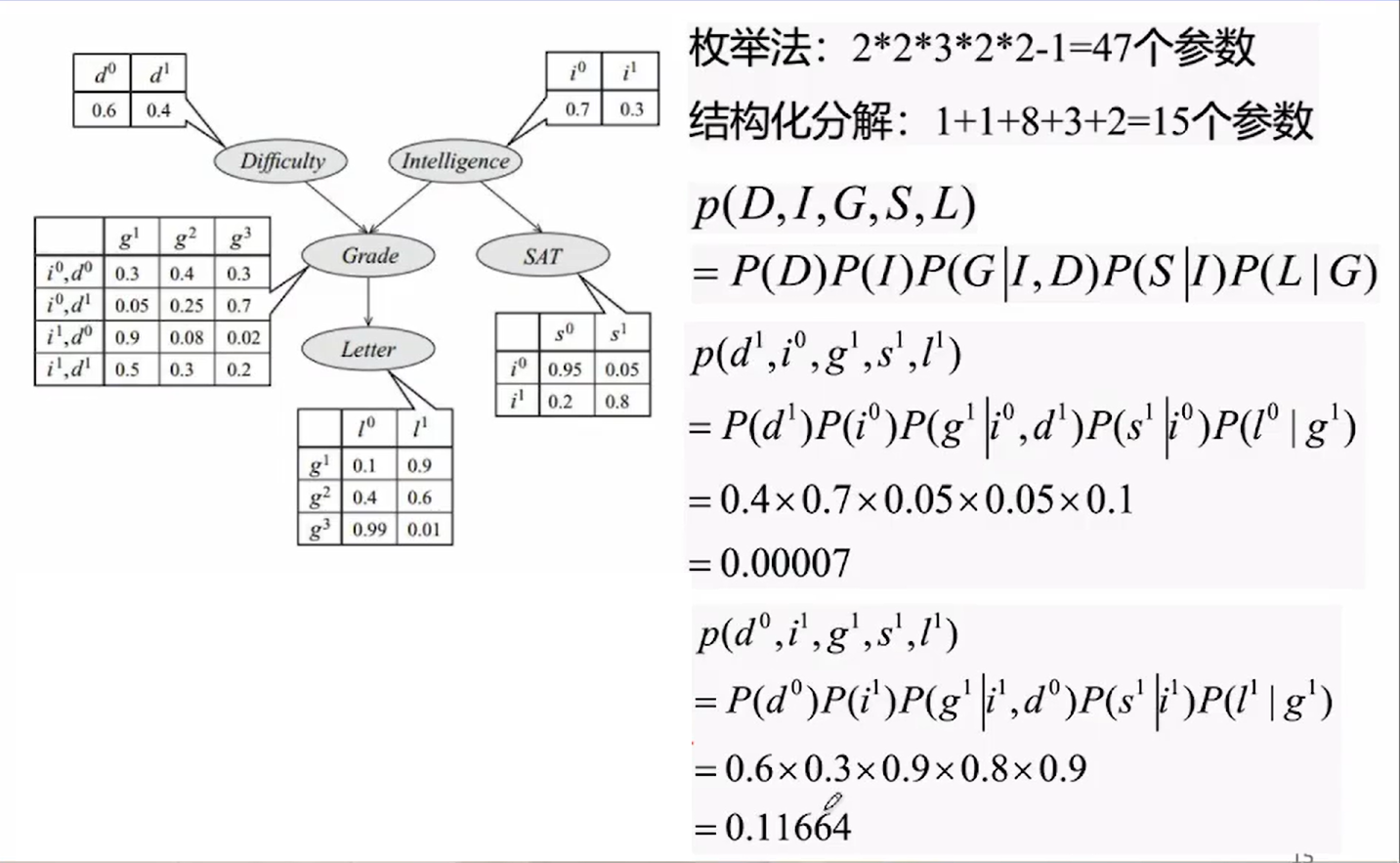
有用的学习资料:NOTE|CS 228: Probabilistic Graphical Models
概率图模型 (Probabilistic Graphical Model )是用图论方法以表现数个独立随机变量之关联的一种建模法。其中有向图又叫做贝叶斯网络 (Bayesian Network ),无向图又叫做马尔可夫随机场 (Markov Random Field )。
为什么要引入概率图模型?
图模型使得联合概率分布的分解可视化了,使得一些变量之间的条件独立关系能够很容易的从图中观测出来;
一些概率上的复杂的计算可以理解为图上的信息传递,这时我们就无需关注太多的复杂表达式。
贝叶斯网络
【西电数模国赛培训】0706概率图模型及其应用 贝叶斯网络 是一种概率图型模型,借由有向无环图(Directed Acyclic Graphs , DAGs )中得知一组随机变量{ X 1 , X 2 , . . . , X n } \{X_{1},X_{2},...,X_{n}\} { X 1 , X 2 , ... , X n } n n n Parents )”,另一个是“果(Children )”,两节点就会产生一个条件概率值。B N = ( G , P ) BN = (G, P) BN = ( G , P ) G = ( V , E ) G = (V, E) G = ( V , E )
V V V E E E P P P Conditional Probability Table ,CPT ),定量描述其所有父节点对该节点的作用效果。
条件独立
关于多变量概率分布的一个重要概念是条件独立性 (Dawid, 1980)。考虑三个变量 a a a b b b c c c b b b c c c a a a b b b
p ( a ∣ b , c ) = p ( a ∣ c ) \begin{align}
p(a|b,c) = p(a|c)
\end{align}
p ( a ∣ b , c ) = p ( a ∣ c )
我们称,给定 c c c a a a b b b c c c a a a b b b
p ( a , b ∣ c ) = p ( a ∣ b , c ) p ( b ∣ c ) = p ( a ∣ c ) p ( b ∣ c ) \begin{align}
p(a,b|c) &= p(a|b,c)p(b|c) \notag \\
&= p(a|c)p(b|c)
\end{align}
p ( a , b ∣ c ) = p ( a ∣ b , c ) p ( b ∣ c ) = p ( a ∣ c ) p ( b ∣ c )
这里我们结合使用了概率的乘积规则以及公式(8.20)。因此我们看到,在给定 c c c a a a b b b a a a b b b c c c c c c a a a b b b c c c
a ⊥ b ∣ c \begin{align}
a \perp b \mid c
\end{align}
a ⊥ b ∣ c
表示给定 c c c a a a b b b
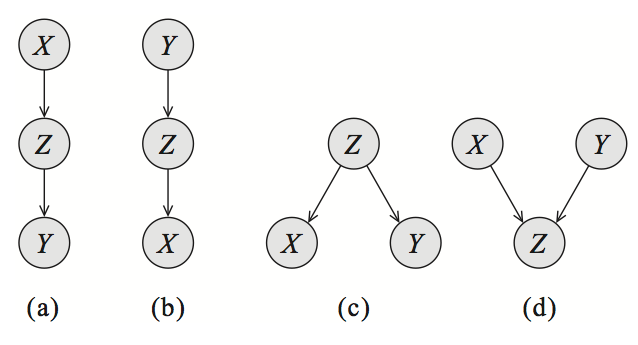
如图 “三变量的贝叶斯网络” 所示,图(a)(b)(c)中的变量X X X Y Y Y Z Z Z X X X Y Y Y Z Z Z
条件独立性性质在将概率模型用于模式识别时扮演着重要角色,它通过简化模型的结构以及在该模型下执行推断和学习所需的计算来实现这一点。我们很快将看到相关的例子。
如果给定一个关于一组变量联合分布的表达式(以条件分布的乘积形式给出,即构成有向图基础的数学表示),那么我们原则上可以通过重复应用概率的求和规则与乘积规则,来检验任何潜在的条件独立性性质是否成立。然而在实践中,这种方法会非常耗时。图模型一个重要且优雅的特点是,联合分布的条件独立性性质可以直接从图中读取,而无需进行任何解析演算。实现这一点的通用框架被称为 d d d d d d d d d d d d
隐马尔科夫模型
【西电数模】【2024年数模国赛培训】7.9 下午7-8节几类概率图模型及其应用-朱明敏】
前置知识:马尔科夫链
状态空间 (State Space ):马尔科夫链所有可能状态的集合,通常记为 S = { s 1 , s 2 , s 3 , . . . , s k } S = \{s_1, s_2, s_3, ..., s_k\} S = { s 1 , s 2 , s 3 , ... , s k } 转移概率 (Transition Probability ):从当前状态 i i i j j j
p i j = P ( X n + 1 = j ∣ X n = i ) \begin{align}
p_{ij} = P(X_{n+1} = j | X_n = i)
\end{align}
p ij = P ( X n + 1 = j ∣ X n = i )
这里假设时间步长是离散的(n = 0 , 1 , 2 , . . . n=0, 1, 2, ... n = 0 , 1 , 2 , ... p i j p_{ij} p ij n n n
转移概率矩阵 (Transition Probability Matrix ):一个方阵 P P P [ P ] i j = p i j [P]_{ij} = p_{ij} [ P ] ij = p ij i i i j j j
P = [ p 11 p 12 ⋯ p 1 k p 21 p 22 ⋯ p 2 k ⋮ ⋮ ⋱ ⋮ p k 1 p k 2 ⋯ p k k ] P = \begin{bmatrix}
p_{11} & p_{12} & \cdots & p_{1k} \\
p_{21} & p_{22} & \cdots & p_{2k} \\
\vdots & \vdots & \ddots & \vdots \\
p_{k1} & p_{k2} & \cdots & p_{kk}
\end{bmatrix} P = p 11 p 21 ⋮ p k 1 p 12 p 22 ⋮ p k 2 ⋯ ⋯ ⋱ ⋯ p 1 k p 2 k ⋮ p kk
马尔科夫性质
过程在将来时刻 t n + 1 t_{n+1} t n + 1 X t n + 1 X_{t_{n+1}} X t n + 1 t n t_n t n X t n X_{t_n} X t n t 1 , t 2 , . . . , t n − 1 t_1, t_2, ..., t_{n-1} t 1 , t 2 , ... , t n − 1 X t 1 , X t 2 , . . . , X t n − 1 X_{t_1}, X_{t_2}, ..., X_{t_{n-1}} X t 1 , X t 2 , ... , X t n − 1
P ( X t n + 1 = x j ∣ X t 1 = x i 1 , X t 2 = x i 2 , . . . , X t n = x i n ) = P ( X t n + 1 = x j ∣ X t n = x i n ) \begin{align}
P(X_{t_{n+1}} = x_{j} | X_{t_1} = x_{i_1}, X_{t_2} = x_{i_2}, ..., X_{t_n}= x_{i_n}) = P(X_{t_{n+1}} = x_{j} | X_{t_n} = x_{i_n})
\end{align}
P ( X t n + 1 = x j ∣ X t 1 = x i 1 , X t 2 = x i 2 , ... , X t n = x i n ) = P ( X t n + 1 = x j ∣ X t n = x i n )
其中 x j x_j x j x i 1 , . . . , x i n x_{i_1}, ..., x_{i_n} x i 1 , ... , x i n
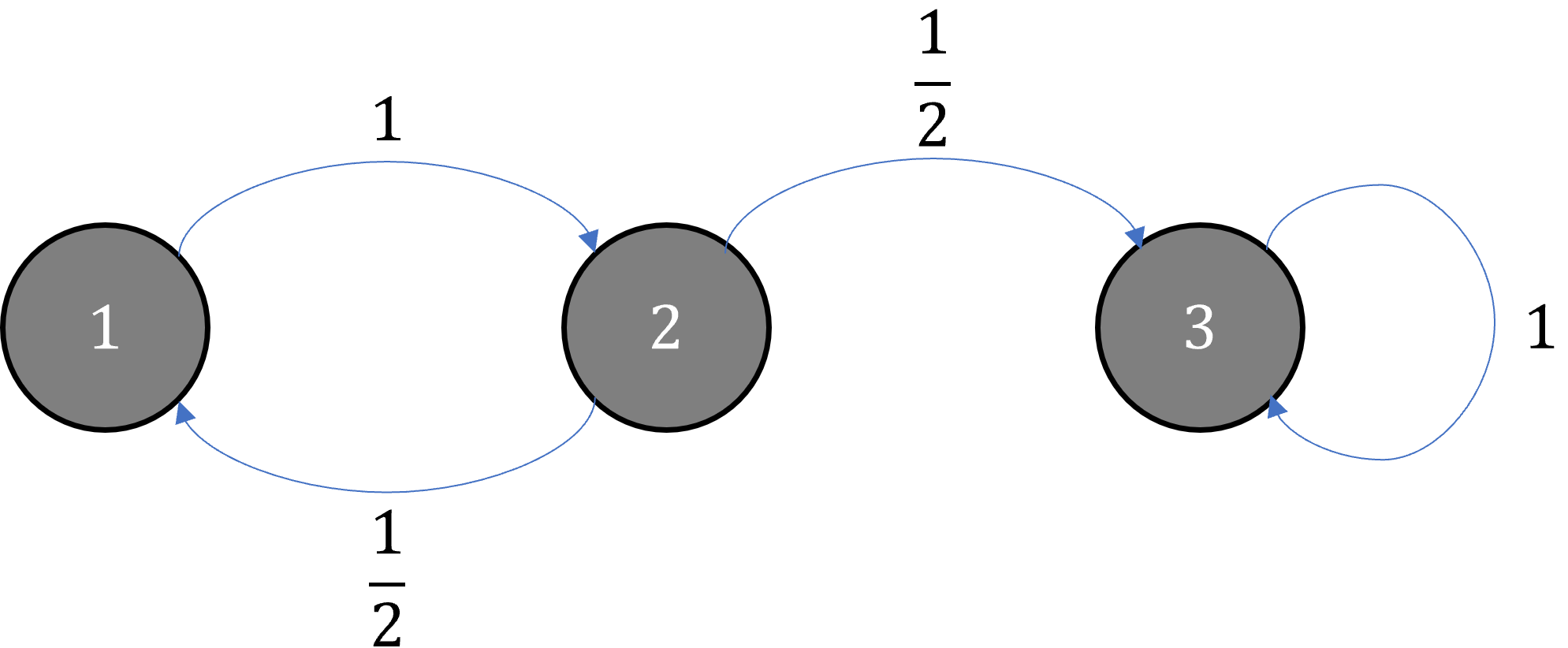
例题#1:天气预测模型
假设某个地方的天气只有两种状态:晴天(Sunny, S)和雨天(Rainy, R)。气象学家根据历史数据观察到以下天气变化规律:问题 1: 如果今天是晴天(X 0 = S X_0 = S X 0 = S P ( X 1 = R ∣ X 0 = S ) = p S R = 0.2 P(X_1 = R | X_0 = S) = p_{SR} = 0.2 P ( X 1 = R ∣ X 0 = S ) = p SR = 0.2 X 2 X_2 X 2 X 1 X_1 X 1 → 0.8 \overset{0.8}{\to} → 0.8 → 0.2 \overset{0.2}{\to} → 0.2 p S S ∗ p S R = 0.8 ∗ 0.2 = 0.16 p_{SS} * p_{SR} = 0.8 * 0.2 = 0.16 p SS ∗ p SR = 0.8 ∗ 0.2 = 0.16 → 0.2 \overset{0.2}{\to} → 0.2 → 0.6 \overset{0.6}{\to} → 0.6 p S R ∗ p R R = 0.2 ∗ 0.6 = 0.12 p_{SR} * p_{RR} = 0.2 * 0.6 = 0.12 p SR ∗ p RR = 0.2 ∗ 0.6 = 0.12
P ( X 2 = R ∣ X 0 = S ) = ( 0.8 ∗ 0.2 ) + ( 0.2 ∗ 0.6 ) = 0.16 + 0.12 = 0.28 P(X_2 = R | X_0 = S) = (0.8 * 0.2) + (0.2 * 0.6) = 0.16 + 0.12 = 0.28
P ( X 2 = R ∣ X 0 = S ) = ( 0.8 ∗ 0.2 ) + ( 0.2 ∗ 0.6 ) = 0.16 + 0.12 = 0.28
解答 1c :P ( 2 ) = P 2 P^{(2)} = P^2 P ( 2 ) = P 2
P 2 = [ 0.8 0.2 0.4 0.6 ] [ 0.8 0.2 0.4 0.6 ] = [ 0.72 0.28 0.56 0.44 ] P^2 = \begin{bmatrix} 0.8 & 0.2 \\ 0.4 & 0.6 \end{bmatrix} \begin{bmatrix} 0.8 & 0.2 \\ 0.4 & 0.6 \end{bmatrix} = \begin{bmatrix}
0.72 & 0.28 \\
0.56 & 0.44
\end{bmatrix} P 2 = [ 0.8 0.4 0.2 0.6 ] [ 0.8 0.4 0.2 0.6 ] = [ 0.72 0.56 0.28 0.44 ]
P 2 P^2 P 2 [ P 2 ] i j [P^2]_{ij} [ P 2 ] ij i i i j j j
我们关心从状态 S S S R R R
查看 P 2 P^2 P 2 [ P 2 ] S R = 0.28 [P^2]_{SR} = 0.28 [ P 2 ] SR = 0.28 P ( X 2 = R ∣ X 0 = S ) = 0.28 P(X_2 = R | X_0 = S) = 0.28 P ( X 2 = R ∣ X 0 = S ) = 0.28
问题 2:从长远来看(即经过很多很多天后),这个地方是晴天和雨天的概率分别是多少?
{ π S p S S + π R p R S = π S π S p S R + π R p R R = π R 且 π S + π R = 1 , π S ≥ 0 , π R ≥ 0 \begin{cases} \pi_S p_{SS} + \pi_R p_{RS} = \pi_S \\ \pi_S p_{SR} + \pi_R p_{RR} = \pi_R \end{cases} \quad \text{且} \quad \pi_S + \pi_R = 1, \quad \pi_S \geq 0, \quad \pi_R \geq 0
{ π S p SS + π R p RS = π S π S p SR + π R p RR = π R 且 π S + π R = 1 , π S ≥ 0 , π R ≥ 0
将转移概率代入方程组:
{ π S ∗ 0.8 + π R ∗ 0.4 = π S ( 1 ) π S ∗ 0.2 + π R ∗ 0.6 = π R ( 2 ) π S + π R = 1 ( 3 ) \begin{cases} \pi_S * 0.8 + \pi_R * 0.4 = \pi_S \quad & (1) \\ \pi_S * 0.2 + \pi_R * 0.6 = \pi_R \quad & (2) \\ \pi_S + \pi_R = 1 \quad & (3) \end{cases}
⎩ ⎨ ⎧ π S ∗ 0.8 + π R ∗ 0.4 = π S π S ∗ 0.2 + π R ∗ 0.6 = π R π S + π R = 1 ( 1 ) ( 2 ) ( 3 )
由方程 (1)得
⇒ π S = 2 π R ( 4 ) \Rightarrow \pi_S = 2\pi_R \quad (4)
⇒ π S = 2 π R ( 4 )
将 (4) 代入 (3):
2 π R + π R = 1 2\pi_R + \pi_R = 1
2 π R + π R = 1
3 π R = 1 3\pi_R = 1
3 π R = 1
π R = 1 3 ≈ 0.3333 \pi_R = \frac{1}{3} \approx 0.3333
π R = 3 1 ≈ 0.3333
代入 (4):
π S = 2 ∗ 1 3 = 2 3 ≈ 0.6667 \pi_S = 2 * \frac{1}{3} = \frac{2}{3} \approx 0.6667
π S = 2 ∗ 3 1 = 3 2 ≈ 0.6667
因此,从长远来看,这个地方是晴天的概率约为 66.67%,是雨天的概率约为33.33%。无论今天是什么天气,经过足够长的时间后,天气分布都会稳定在这个比例上。
常返性
假设一个马尔科夫链从状态i i i
p i = P ( 永远返回状态 i ) = 1 \begin{align}
p_{i} = P(永远返回状态i) = 1
\end{align}
p i = P ( 永远返回状态 i ) = 1
则称状态i i i 常返的 (Recurrent )。若p i < 1 p_{i} < 1 p i < 1 i i i 瞬态 (Transient )。X = { X 0 , X 1 , ⋯ , X t , ⋯ } X = \{X_0, X_1, \cdots, X_t, \cdots\} X = { X 0 , X 1 , ⋯ , X t , ⋯ } S S S i , j ∈ S i, j \in S i , j ∈ S p i j ( t ) p_{ij}^{(t)} p ij ( t ) 0 0 0 j j j t t t i i i
p i j ( t ) = P ( X t = i , X s ≠ i , s = 1 , 2 , ⋯ , t − 1 ∣ X 0 = j ) , t = 1 , 2 , ⋯ \begin{align}
p_{ij}^{(t)} = P(X_t = i, X_s \neq i, s = 1, 2, \cdots, t - 1|X_0 = j), \quad t = 1, 2, \cdots
\end{align}
p ij ( t ) = P ( X t = i , X s = i , s = 1 , 2 , ⋯ , t − 1∣ X 0 = j ) , t = 1 , 2 , ⋯
若对所有状态 i , j i, j i , j lim t → ∞ p i j ( t ) > 0 \lim_{t \to \infty} p_{ij}^{(t)} > 0 lim t → ∞ p ij ( t ) > 0 X X X 正常返的 (Positive Recurrent )。i ∈ S i \in S i ∈ S
μ i = E [ T i ∣ X 0 = i ] = ∞ \begin{align}
\mu_i = \mathbb{E}[T_i \mid X_0 = i] = \infty
\end{align}
μ i = E [ T i ∣ X 0 = i ] = ∞
即稳态概率
π i = 1 E [ T i ∣ X 0 = i ] = 0 \begin{align}
\pi_{i} = \frac{1}{\mathbb{E}[T_i \mid X_0 = i]} = 0
\end{align}
π i = E [ T i ∣ X 0 = i ] 1 = 0
则称状态 i i i 零常返的 (Null Recurrent )。若马尔可夫链的所有常返状态均为零常返,则称该链为零常返的。
周期性
设状态i i i P i i ( n ) > 0 P_{ii}^{(n)} > 0 P ii ( n ) > 0 n ( n ≥ 1 ) n(n\geq1) n ( n ≥ 1 ) i i i d i d_{i} d i
马尔科夫链的可约与不可约
设有马尔可夫链 X = X 0 , X 1 , ⋯ , X t , ⋯ X = {X_0, X_1, \cdots, X_t, \cdots} X = X 0 , X 1 , ⋯ , X t , ⋯ S S S i , j ∈ S i, j \in S i , j ∈ S t ( t > 0 ) t(t > 0) t ( t > 0 )
P ( X t = i ∣ X 0 = j ) > 0 \begin{align}
P(X_t = i|X_0 = j) > 0
\end{align}
P ( X t = i ∣ X 0 = j ) > 0
即时刻 0 0 0 j j j t t t i i i 0 0 0 X X X 不可约的 (Irreducible );否则称马尔可夫链是可约的 (Reducible )。可约链在大多数应用领域无实际价值,因此通常只研究不可约链。
不可约、非周期且正常返的马尔科夫链有唯一平稳分布存在。
同时具有正常返和零常返的马尔科夫链是可约的。
可逆的马尔科夫链
设有马尔可夫链 X = { X 0 , X 1 , ⋯ , X t , ⋯ } X = \{X_0, X_1, \cdots, X_t, \cdots\} X = { X 0 , X 1 , ⋯ , X t , ⋯ } S S S P P P π = ( π 1 , π 2 , ⋯ ) T \pi = (\pi_1, \pi_2, \cdots)^T π = ( π 1 , π 2 , ⋯ ) T i , j ∈ S i, j \in S i , j ∈ S t t t
P ( X t = i ∣ X t − 1 = j ) π j = P ( X t − 1 = j ∣ X t = i ) π i , i , j = 1 , 2 , ⋯ P(X_t = i|X_{t-1} = j) \pi_j = P(X_{t-1} = j|X_t = i) \pi_i, \quad i, j = 1, 2, \cdots
P ( X t = i ∣ X t − 1 = j ) π j = P ( X t − 1 = j ∣ X t = i ) π i , i , j = 1 , 2 , ⋯
或简写为
p j i π j = p i j π i , i , j = 1 , 2 , ⋯ \begin{align}
p_{ji} \pi_j = p_{ij} \pi_i, \quad i, j = 1, 2, \cdots
\end{align}
p ji π j = p ij π i , i , j = 1 , 2 , ⋯
则称此马尔可夫链 X X X 可逆马尔可夫链 (Reversible Markov Chain )。
隐马尔科夫模型的基本概念
隐马尔科夫模型 (Hidden Markov Model ,HMM )是关于时序的概率模型,描述由一个隐藏的马尔科夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测从而产生观测随机序列的过程。隐藏的马尔科夫链随机生成的状态的序列称为状态序列 (State Sequence );每个状态生成一个观测,而由此产生的观测的随机序列称为观测序列 (Observation Sequence )。序列的每一个位置又可以看作是一个时刻。
隐马尔科夫模型是一种特殊的贝叶斯网络。
所有可能的状态的集合Q = { q 1 , q 2 , … , q N } Q = \{q_{1},q_{2},\dots,q_{N}\} Q = { q 1 , q 2 , … , q N } V = { v 1 , v 2 , ⋯ , v M } V = \{v_1, v_2, \cdots, v_M\} V = { v 1 , v 2 , ⋯ , v M } N N N M M M I = ( i 1 , i 2 , ⋯ , i T ) I = (i_1, i_2, \cdots, i_T) I = ( i 1 , i 2 , ⋯ , i T ) T T T O = ( o 1 , o 2 , ⋯ , o T ) O = (o_1, o_2, \cdots, o_T) O = ( o 1 , o 2 , ⋯ , o T ) A = [ a i j ] N × N A = [a_{ij}]_{N \times N} A = [ a ij ] N × N a i j = P ( i t + 1 = q j ∣ i t = q i ) , i = 1 , 2 , ⋯ , N , j = 1 , 2 , ⋯ , N a_{ij} = P(i_{t+1} = q_j | i_t = q_i), \quad i = 1, 2, \cdots, N, \quad j = 1, 2, \cdots, N a ij = P ( i t + 1 = q j ∣ i t = q i ) , i = 1 , 2 , ⋯ , N , j = 1 , 2 , ⋯ , N t t t q i q_i q i t + 1 t + 1 t + 1 q j q_j q j B = [ b j ( k ) ] N × M B = [b_j(k)]_{N \times M} B = [ b j ( k ) ] N × M b j ( k ) = P ( o t = v k ∣ i t = q j ) , k = 1 , 2 , ⋯ , M , j = 1 , 2 , ⋯ , N b_j(k) = P(o_t = v_k|i_t = q_j), \quad k = 1, 2, \cdots, M, \quad j = 1, 2, \cdots, N b j ( k ) = P ( o t = v k ∣ i t = q j ) , k = 1 , 2 , ⋯ , M , j = 1 , 2 , ⋯ , N t t t q j q_j q j v k v_k v k π = ( π i ) \pi = (\pi_i) π = ( π i ) π i = P ( i 1 = q i ) , i = 1 , 2 , ⋯ , N \pi_i = P(i_1 = q_i), \quad i = 1, 2, \cdots, N π i = P ( i 1 = q i ) , i = 1 , 2 , ⋯ , N t = 1 t = 1 t = 1 q i q_i q i π \pi π A A A B B B π \pi π A A A B B B λ \lambda λ
λ = ( A , B , π ) \begin{align}
\lambda = (A, B, \pi)
\end{align}
λ = ( A , B , π )
A , B , π A, B, \pi A , B , π 隐马尔可夫模型的三要素 。A A A π \pi π B B B
从定义可知,隐马尔可夫模型作了两个基本假设:
齐次马尔可夫性假设 ,即假设隐藏的马尔可夫链在任意时刻 t t t t t t
P ( i t ∣ i t − 1 , o t − 1 , ⋯ , i 1 , o 1 ) = P ( i t ∣ i t − 1 ) , t = 1 , 2 , ⋯ , T \begin{align}
P(i_t|i_{t-1}, o_{t-1}, \cdots, i_1, o_1) = P(i_t|i_{t-1}), \quad t = 1, 2, \cdots, T
\end{align}
P ( i t ∣ i t − 1 , o t − 1 , ⋯ , i 1 , o 1 ) = P ( i t ∣ i t − 1 ) , t = 1 , 2 , ⋯ , T
观测独立性假设 ,即假设任意时刻的观测只依赖于该时刻的马尔可夫链的状态,与其他观测及状态无关:
P ( o t ∣ i T , o T , i T − 1 , o T − 1 , ⋯ , i t + 1 , o t + 1 , i t , i t − 1 , o t − 1 , ⋯ , i 1 , o 1 ) = P ( o t ∣ i t ) \begin{align}
P(o_t|i_T, o_T, i_{T-1}, o_{T-1}, \cdots, i_{t+1}, o_{t+1}, i_t, i_{t-1}, o_{t-1}, \cdots, i_1, o_1) = P(o_t|i_t)
\end{align}
P ( o t ∣ i T , o T , i T − 1 , o T − 1 , ⋯ , i t + 1 , o t + 1 , i t , i t − 1 , o t − 1 , ⋯ , i 1 , o 1 ) = P ( o t ∣ i t )
例题#2:盒子和球模型
概率计算方法
隐马尔可夫模型(HMM)前向算法
\begin{algorithm}
\caption{Forward Algorithm}
\begin{algorithmic}
\Require 隐马尔可夫模型 $\lambda = (A, B, \pi)$,观测序列 $O = (o_1, o_2, \dots, o_T)$
\Ensure 观测序列概率 $P(O|\lambda)$
\State \textbf{初始化} ($t=1$):\\
$\alpha_1(i) = \pi_i b_i(o_1), \quad i = 1, 2, \dots, N$
\State \textbf{递推} ($t=2$ 到 $T$):
\For{$t = 2$ \To $T$}
\For{$i = 1$ \To $N$}
\State $\alpha_t(i) = \left[ \sum_{j=1}^N \alpha_{t-1}(j) a_{ji} \right] b_i(o_t)$
\EndFor
\EndFor
\State \textbf{计算总概率}:
\State $P(O|\lambda) = \sum_{i=1}^N \alpha_T(i)$
\end{algorithmic}
\end{algorithm}
\begin{algorithm}
\caption{Backward Algorithm}
\begin{algorithmic}
\Require 隐马尔可夫模型 $\lambda = (A, B, \pi)$,观测序列 $O = (o_1, o_2, \dots, o_T)$
\Ensure 观测序列概率 $P(O|\lambda)$
\State \textbf{初始化} ($t=T$):
\For{$i = 1$ \To $N$}
\State $\beta_T(i) = 1$
\EndFor
\State \textbf{递推} ($t=T-1$ 到 $1$):
\For{$t = T-1$ \Downto $1$}
\For{$i = 1$ \To $N$}
\State $\beta_t(i) = \sum_{j=1}^N a_{ij} b_j(o_{t+1}) \beta_{t+1}(j)$
\EndFor
\EndFor
\State \textbf{计算总概率}:
\State $P(O|\lambda) = \sum_{i=1}^N \pi_i b_i(o_1) \beta_1(i)$
\end{algorithmic}
\end{algorithm}
前向算法与后向算法的具体实现见下面。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 import numpy as npclass HMM : def __init__ (self, A, B, pi ): """ 初始化HMM模型参数 参数: A -- 状态转移矩阵 (N x N) B -- 观测概率矩阵 (N x M) pi -- 初始状态概率向量 (N) """ self .A = np.array(A) self .B = np.array(B) self .pi = np.array(pi) self .N = len (pi) self .M = self .B.shape[1 ] def forward (self, obs ): """ 前向算法 返回: 前向概率矩阵alpha和观测序列概率P(O|λ) """ T = len (obs) alpha = np.zeros((T, self .N)) alpha[0 ] = self .pi * self .B[:, obs[0 ]] for t in range (1 , T): for j in range (self .N): alpha[t, j] = np.sum (alpha[t-1 ] * self .A[:, j]) * self .B[j, obs[t]] prob = np.sum (alpha[-1 ]) return alpha, prob def backward (self, obs ): """ 后向算法 返回: 后向概率矩阵beta """ T = len (obs) beta = np.zeros((T, self .N)) beta[-1 ] = 1.0 for t in range (T-2 , -1 , -1 ): for i in range (self .N): beta[t, i] = np.sum ( self .A[i, :] * self .B[:, obs[t+1 ]] * beta[t+1 , :] ) prob = np.sum (self .pi * self .B[:, obs[0 ]] * beta[0 ]) return beta, prob hmm = HMM( A=[[0.5 ,0.2 , 0.3 ], [0.3 ,0.5 ,0.2 ], [0.2 ,0.3 ,0.5 ]], B=[[0.5 ,0.5 ], [0.4 ,0.6 ], [0.7 ,0.3 ]], pi=[0.2 ,0.4 ,0.4 ] ) obs_seq = [0 , 1 , 0 ] alpha, prob_forward = hmm.forward(obs_seq) print ("前向概率矩阵alpha:" )print (alpha)print (f"前向算法计算的观测序列概率: {prob_forward:.6 f} \n" )beta, prob_backward = hmm.backward(obs_seq) print ("后向概率矩阵beta:" )print (beta)print (f"后向算法计算的观测序列概率: {prob_backward:.6 f} \n" )print (f"概率一致性检查: {np.isclose(prob_forward, prob_backward)} \n" )
学习算法
\begin{algorithm}
\caption{Baum-Welch Algorithm}
\begin{algorithmic}
\Require 观测序列 $O = (o_1, o_2, \dots, o_T)$
\Ensure 隐马尔可夫模型参数 $\lambda$
\State \textbf{初始化}:
\State 对 $n=0$,选取 $a_{ij}^{(0)}$, $b_j(k)^{(0)}$, $\pi_i^{(0)}$,得到模型 $\lambda^{(0)} = (A^{(0)}, B^{(0)}, \pi^{(0)})$
\State \textbf{递推}:
\For{$n = 1, 2, \dots$}
\State $a_{ij}^{(n+1)} = \dfrac{\sum_{t=1}^{T-1} \xi_t(i,j)}{\sum_{t=1}^{T-1} \gamma_t(i)}$
\State $b_j(k)^{(n+1)} = \dfrac{\sum_{t=1}^{T} \gamma_t(j)}{\sum_{t=1}^{T} \gamma_t(j)}$
\State $\pi_i^{(n+1)} = \gamma_1(i)$
\State 右端各值按观测 $O$ 和模型 $\lambda^{(n)} = (A^{(n)}, B^{(n)}, \pi^{(n)})$ 计算
\EndFor
\State \textbf{终止}:
\State 得到模型参数 $\lambda^{(n+1)} = (A^{(n+1)}, B^{(n+1)}, \pi^{(n+1)})$
\end{algorithmic}
\end{algorithm}
预测算法
\begin{algorithm}
\caption{Viterbi Algorithm}
\begin{algorithmic}
\Require 模型 $\lambda = (A, B, \pi)$ 和观测 $O = (o_1, o_2, \dots, o_T)$
\Ensure 最优路径 $I^* = (i_1^*, i_2^*, \dots, i_T^*)$
\State \textbf{初始化}:
\For{$i = 1$ \To $N$}
\State $\delta_1(i) = \pi_i b_i(o_1)$
\State $\Psi_1(i) = 0$
\EndFor
\State \textbf{递推}:
\For{$t = 2$ \To $T$}
\For{$i = 1$ \To $N$}
\State $\delta_t(i) = \max_{1 \leq j \leq N} [\delta_{t-1}(j)a_{ji}]b_i(o_t)$
\State $\Psi_t(i) = \arg\max_{1 \leq j \leq N} [\delta_{t-1}(j)a_{ji}]$
\EndFor
\EndFor
\State \textbf{终止}:
\State $P^* = \max_{1 \leq i \leq N} \delta_T(i)$
\State $i_T^* = \arg\max_{1 \leq i \leq N} [\delta_T(i)]$
\State \textbf{最优路径回溯}:
\For{$t = T-1$ \Downto $1$}
\State $i_t^* = \Psi_{t+1}(i_{t+1}^*)$
\EndFor
\State 求得最优路径 $I^* = (i_1^*, i_2^*, \dots, i_T^*)$
\end{algorithmic}
\end{algorithm}
马尔科夫随机场
模型定义
给定一个联合概率分布P ( Y ) P(Y) P ( Y ) G G G
成对马尔科夫性(pairwise Markov property )
设u u u v v v G G G u u u v v v Y u Y_u Y u Y v Y_v Y v O O O Y O Y_{O} Y O Y O Y_{O} Y O Y u Y_{u} Y u Y v Y_{v} Y v
P ( Y u , Y v ∣ Y O ) = P ( Y u ∣ Y O ) P ( Y v ∣ Y O ) \begin{align}
P(Y_{u},Y_{v}|Y_{O}) = P(Y_{u}|Y_{O})P(Y_{v}|Y_{O})
\end{align}
P ( Y u , Y v ∣ Y O ) = P ( Y u ∣ Y O ) P ( Y v ∣ Y O )
局部马尔科夫性(local Markov property )
设v ∈ V v \in V v ∈ V G G G W W W v v v O O O v v v W W W v v v Y v Y_v Y v W W W Y W Y_{W} Y W O O O Y O Y_{O} Y O Y W Y_{W} Y W Y v Y_v Y v Y O Y_{O} Y O
P ( Y v , Y O ∣ Y W ) = P ( Y v ∣ Y W ) P ( Y O ∣ Y W ) \begin{align}
P(Y_{v},Y_{O}|Y_{W}) = P(Y_{v}|Y_{W})P(Y_{O}|Y_{W})
\end{align}
P ( Y v , Y O ∣ Y W ) = P ( Y v ∣ Y W ) P ( Y O ∣ Y W )
全局马尔科夫性(global Markov property )
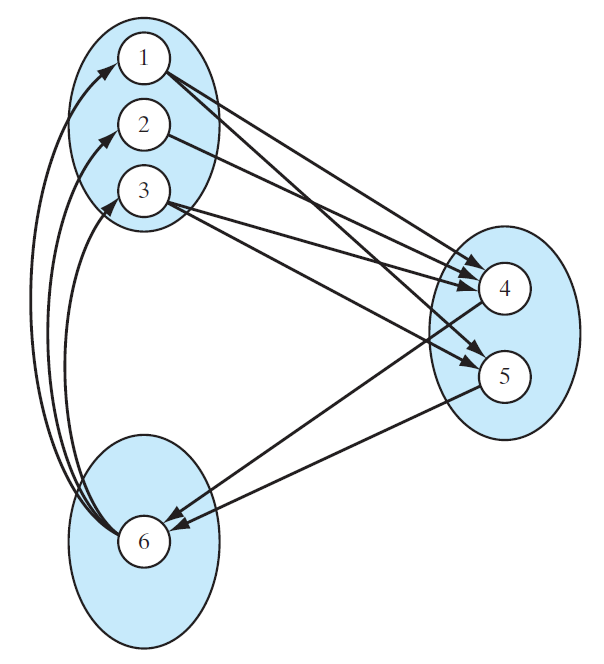
设A A A B B B C C C C C C G G G A A A B B B A A A B B B C C C Y A Y_{A} Y A Y B Y_{B} Y B Y C Y_{C} Y C Y C Y_{C} Y C Y A Y_{A} Y A Y B Y_{B} Y B
P ( Y A , Y B ∣ Y C ) = P ( Y A ∣ Y C ) P ( Y B ∣ Y C ) \begin{align}
P(Y_{A}, Y_{B} \mid Y_{C}) = P(Y_{A} \mid Y_{C}) P(Y_{B} \mid Y_{C})
\end{align}
P ( Y A , Y B ∣ Y C ) = P ( Y A ∣ Y C ) P ( Y B ∣ Y C )
当我们需要用无向图建模随机变量之间的依赖关系时,如何保证联合概率分布与图结构一致?对于这种情况,我们引进如下概念:P ( Y ) P(Y) P ( Y ) G = ( V , E ) G = (V,E) G = ( V , E ) G G G P ( Y ) P(Y) P ( Y ) 概率无向图模型 (Probabilistic Undirected Graphical Model )也称马尔可夫随机场 (Markov Random Field )。
马尔科夫随机场的因子分解
设C C C G G G C C C C C C 团 (clique );若C C C G G G G G G C C C 最大团 (maximal clique )。将概率无向图模型的联合概率分布表示为其最大团上的随机变量的函数的乘积形式的操作,称为概率无向图模型的因式分解 。
Hammersley-Clifford定理
设C C C G G G Y C Y_C Y C potential function ) 是指一个定义在Y C Y_C Y C ψ C ( Y C ) \psi_C(Y_C) ψ C ( Y C ) ψ C ( Y C ) = exp ( − E ( Y C ) ) \psi_C(Y_C) = \exp(-E(Y_C)) ψ C ( Y C ) = exp ( − E ( Y C )) E ( Y C ) E(Y_C) E ( Y C ) P ( Y ) P(Y) P ( Y )
P ( Y ) = 1 Z ∏ C ψ C ( Y C ) \begin{align}
P(Y) = \frac{1}{Z} \prod_{C} \psi_C(Y_C)
\end{align}
P ( Y ) = Z 1 C ∏ ψ C ( Y C )
其中Z Z Z
Z = ∑ Y ∏ C ψ C ( Y C ) \begin{align}
Z = \sum_{Y} \prod_{C} \psi_C(Y_C)
\end{align}
Z = Y ∑ C ∏ ψ C ( Y C )
设P P P G G G P ( Y ) > 0 P(Y) > 0 P ( Y ) > 0 P P P G G G P P P G G G C C C ψ C \psi_C ψ C
P ( Y ) = 1 Z ∏ C ∈ C ψ C ( Y C ) \begin{align}
P(Y) = \frac{1}{Z} \prod_{C \in \mathcal{C}} \psi_C(Y_C)
\end{align}
P ( Y ) = Z 1 C ∈ C ∏ ψ C ( Y C )
条件随机场
条件随机场与线性链条件随机场
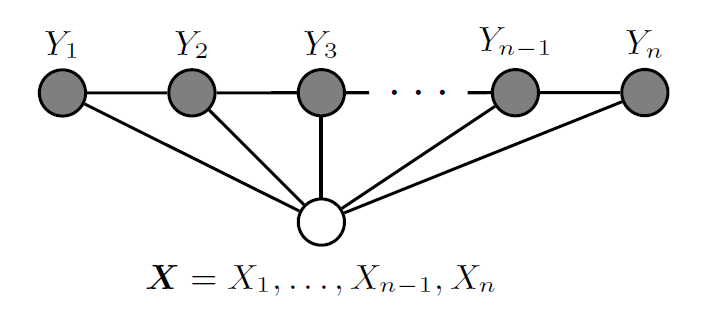
设X X X Y Y Y P ( Y ∣ X ) P(Y|X) P ( Y ∣ X ) X X X Y Y Y Y Y Y G = ( V , E ) G=(V,E) G = ( V , E )
P ( Y v ∣ X , Y w , w ≠ v ) = P ( Y v ∣ X , Y w , w ∼ v ) \begin{align}
P(Y_v | X, Y_w, w \ne v) = P(Y_v | X, Y_w, w \sim v)
\end{align}
P ( Y v ∣ X , Y w , w = v ) = P ( Y v ∣ X , Y w , w ∼ v )
对任意结点v v v P ( Y ∣ X ) P(Y|X) P ( Y ∣ X ) 条件随机场 (Conditional Random Field )。式中w ∼ v w \sim v w ∼ v G = ( V , E ) G=(V,E) G = ( V , E ) v v v w w w w ≠ v w \ne v w = v v v v Y v , Y w Y_v, Y_w Y v , Y w v v v w w w
设X = ( X 1 , X 2 , ⋯ , X n ) X=(X_1,X_2,\cdots,X_n) X = ( X 1 , X 2 , ⋯ , X n ) Y = ( Y 1 , Y 2 , ⋯ , Y n ) Y=(Y_1,Y_2,\cdots,Y_n) Y = ( Y 1 , Y 2 , ⋯ , Y n ) X X X Y Y Y P ( Y ∣ X ) P(Y|X) P ( Y ∣ X )
P ( Y i ∣ X , Y 1 , ⋯ , Y i − 1 , Y i + 1 , ⋯ , Y n ) = P ( Y i ∣ X , Y i − 1 , Y i + 1 ) , i = 1 , 2 , ⋯ , n ( C o n s i d e r o n e − s i d e d c a s e s o n l y a t i = 1 a n d i = n . ) \begin{align}
\begin{array}{c}
P(Y_i | X, Y_1, \cdots, Y_{i-1}, Y_{i+1}, \cdots, Y_n) = P(Y_i | X, Y_{i-1}, Y_{i+1}), \\
i=1,2,\cdots,n(Consider\ one-sided\ cases\ only\ at\ i=1\ and\ i=n.)
\end{array}
\end{align}
P ( Y i ∣ X , Y 1 , ⋯ , Y i − 1 , Y i + 1 , ⋯ , Y n ) = P ( Y i ∣ X , Y i − 1 , Y i + 1 ) , i = 1 , 2 , ⋯ , n ( C o n s i d er o n e − s i d e d c a ses o n l y a t i = 1 an d i = n . )
则称P ( Y ∣ X ) P(Y|X) P ( Y ∣ X ) 线性链条件随机场 (Linear Chain Conditional Random Field )。在标注问题中,X X X Y Y Y P ( Y ∣ X ) P(Y|X) P ( Y ∣ X ) X X X x x x Y Y Y y y y 线性链条件随机场的参数化形式 :
P ( y ∣ x ) = 1 Z ( x ) exp ( ∑ i , k λ k t k ( y i − 1 , y i , x , i ) + ∑ i , l μ l s l ( y i , x , i ) ) , \begin{align}
P(y|x) = \frac{1}{Z(x)} \exp \left( \sum_{i,k} \lambda_k t_k (y_{i-1}, y_i, x, i) + \sum_{i,l} \mu_l s_l (y_i, x, i) \right),
\end{align}
P ( y ∣ x ) = Z ( x ) 1 exp i , k ∑ λ k t k ( y i − 1 , y i , x , i ) + i , l ∑ μ l s l ( y i , x , i ) ,
其中规范化因子Z ( x ) Z(x) Z ( x )
Z ( x ) = ∑ y exp ( ∑ i , k λ k t k ( y i − 1 , y i , x , i ) + ∑ i , l μ l s l ( y i , x , i ) ) . \begin{align}
Z(x) = \sum_y \exp \left( \sum_{i,k} \lambda_k t_k (y_{i-1}, y_i, x, i) + \sum_{i,l} \mu_l s_l (y_i, x, i) \right).
\end{align}
Z ( x ) = y ∑ exp i , k ∑ λ k t k ( y i − 1 , y i , x , i ) + i , l ∑ μ l s l ( y i , x , i ) .
式中,t k t_k t k s l s_l s l λ k \lambda_k λ k μ l \mu_l μ l Z ( x ) Z(x) Z ( x )