不错的学习资源:05.07-Support-Vector-Machines.ipynb
支持向量机(Support Vector Machine,SVM)是一种二类分类模型。支持向量机的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。
在样本空间,划分超平面可通过如下线性方程来描述:
wTx+b=0
其中w=(w1;w2;…;wd)为法向量,决定了超平面的方向;b为位移项,决定了超平面与原点的距离。该超平面可以记作(w,b)。

线性可分的支持向量机
给定线性可分训练数据集,通过间隔最大化或等价地求解相应的凸二次规划问题学习得到的分离超平面为
w∗⋅x+b∗=0
以及相应的分类决策函数
f(x)=sign(w∗⋅x+b∗)
称为线性可分支持向量机。
函数间隔与几何间隔
- 函数间隔:超平面(w,b)关于样本点(xi,yi)的函数间隔为
γ^i=yi(w⊤xi+b)
- 几何间隔:超平面(w,b)关于样本点(xi,yi)的几何间隔为
γi=∥w∥γ^i=∥w∥yi(w⊤xi+b)
如果∥w∥=1,那么函数间隔和几何间隔相等,换言之,几何间隔是函数间隔的归一化版本。
间隔最大化
该问题可以表示为以下约束最优化问题:
w,bmaxs.t. γyi(∥w∥w⋅xi+∥w∥b)≥γ,i=1,2,⋯,N
即我们希望最大化超平面 (w,b) 关于训练数据集的几何间隔 γ,约束条件表示超平面 (w,b) 关于每个训练样本点的几何间隔至少是 γ。
考虑几何间隔和函数间隔的关系式,可将问题改写为:
w,bmaxs.t. ∥w∥γ^yi(w⋅xi+b)≥γ^,i=1,2,⋯,N
函数间隔 γ^ 的取值不影响最优化问题的解。假设将 w 和 b 按比例改变为 λw 和 λb,函数间隔变为 λγ^。这一改变对不等式约束和目标函数优化均无影响,因此可取 γ^=1。代入后,最大化 ∥w∥1 等价于最小化 21∥w∥2,于是得到线性可分支持向量机的最优化问题
w,bmins.t. 21∥w∥2yi(w⋅xi+b)−1≥0,i=1,2,⋯,N
\begin{algorithm}
\caption{Maximum Margin Method}
\begin{algorithmic}
\STATE \textbf{输入:} 线性可分训练数据集 $T = \{(x_1, y_1), (x_2, y_2), \cdots, (x_N, y_N)\}$,其中 $x_i \in \mathcal{X} = \mathbb{R}^n$,$y_i \in \mathcal{Y} = \{-1, +1\}, i = 1, 2, \cdots, N$
\STATE \textbf{输出:} 最大间隔分离超平面和分类决策函数
\STATE \textbf{步骤1:构造并求解约束优化问题} \\
$\min_{w, b} \quad \frac{1}{2} \| w \|^2$ \\
$\text{s.t. } \quad y_i(w \cdot x_i + b) \geq \hat{\gamma}, \quad i = 1, 2, \cdots, N $ \\
求解得到最优解 $w^*, b^*$
\STATE \textbf{步骤2:生成分离超平面和分类决策函数}
\STATE 分离超平面:$w^* \cdot x + b^* = 0$
\STATE 分类决策函数:$f(x) = \mathrm{sign}(w^* \cdot x + b^*)$
\STATE \textbf{返回} 分离超平面 $w^* \cdot x + b^* = 0$ 和决策函数 $f(x)$
\end{algorithmic}
\end{algorithm}
支持向量与间隔边界
如下图所示,有三个观测点到最优超平面的距离相等,都等于最大分隔边界, 这样的点称为支持向量。 这些点改变位置会使得分隔线改变位置, 而其它点轻微改变位置则不会使得分隔线改变位置, 除非其它点到分隔线的距离小于分隔边界了。
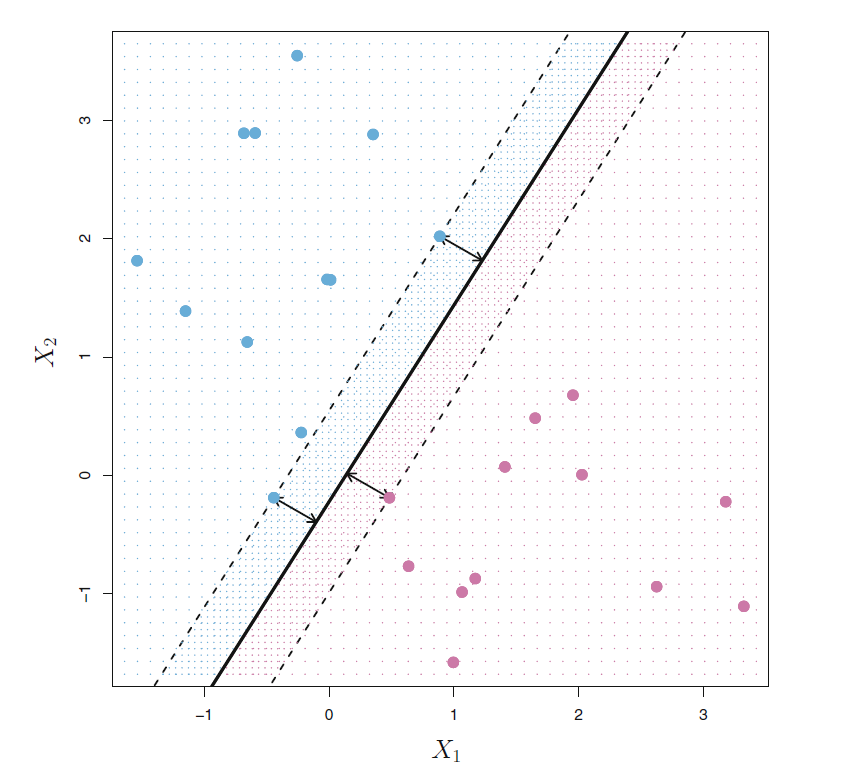
线性支持向量机
给定特征空间上的训练数据集:
T={(x1,y1),(x2,y2),⋯,(xN,yN)}
其中 xi∈X=Rn, yi∈Y={+1,−1}, i=1,2,⋯,N,xi 为特征向量,yi 为类标记。假设训练数据集线性不可分,存在特异点(outlier),除去后大部分样本线性可分。
线性不可分意味着某些样本点 (xi,yi) 不满足约束条件。引入松弛变量 ξi≥0,使约束变为:
yi(w⋅xi+b)≥1−ξi
同时对每个松弛变量支付代价 ξi,目标函数变为:
21∥w∥2+Ci=1∑Nξi
这里 C>0 为惩罚参数,C 值大时对误分类惩罚增大,C 值小时惩罚减小。最小化目标函数使间隔尽量大且误分类点尽量少,C 为调和系数。
线性不可分的线性支持向量机学习问题转化为凸二次规划问题(原始问题):
w,b,ξmins.t. 21∥w∥2+Ci=1∑Nξiyi(w⋅xi+b)≥1−ξi,i=1,2,⋯,Nξi≥0,i=1,2,⋯,N
对于给定的线性不可分的训练数据集,通过求解凸二次规划问题,得到的分离超平面为
w∗⋅x+b∗=0
以及相应的分类决策函数
f(x)=sign(w∗⋅x+b∗)
称为线性支持向量机。
如下图所示,左图中的1号和8号点进入了分隔区域, 右图中的1号和8号点进入了分隔区域, 11和12号点进入了错误的一面。
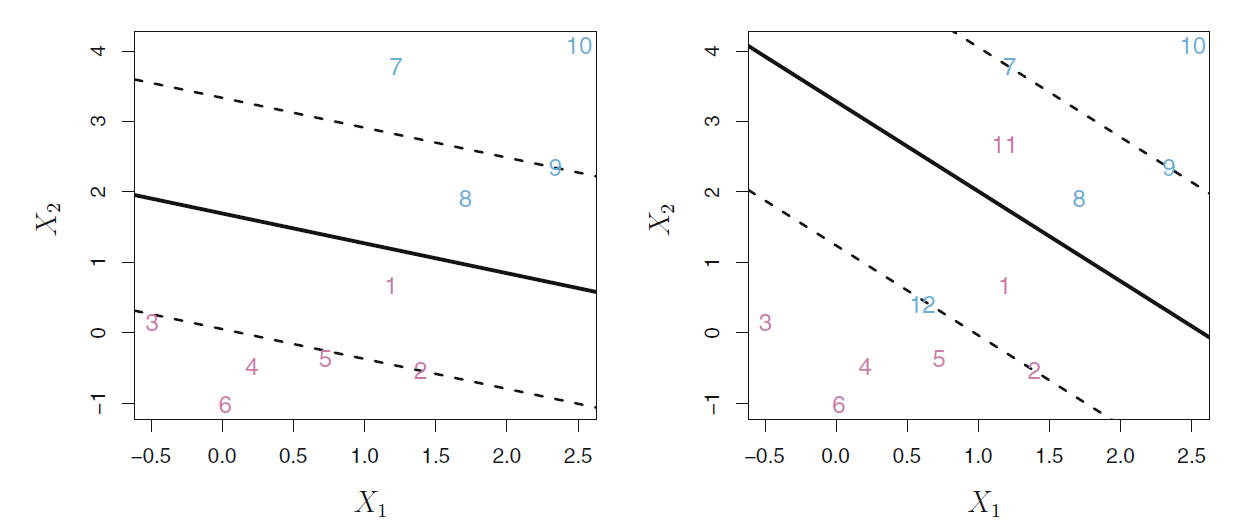
线性支持向量机的模型为分离超平面w∗⋅x+b∗=0及决策函数 f(x)=sign(w∗⋅x+b∗),学习策略为软间隔最大化,学习算法为凸二次规划。另一种解释是最小化目标函数:
i=1∑N[1−yi(w⋅xi+b)]++λ∥w∥2
目标函数第1项是经验风险,函数
L(y(w⋅x+b))=[1−y(w⋅x+b)]+
称为合页损失函数(Hinge Loss Function)。下标"+"表示一下取正值的函数为:
[z]+={z,0,z>0z≤0
当样本点 (xi,yi) 被正确分类且函数间隔 yi(w⋅xi+b)>1 时损失为0,否则损失为 1−yi(w⋅xi+b)。目标函数第2项是系数 λ 的 L2 范数正则化项。
线性支持向量机原始优化问题
w,b,ξmins.t. 21∥w∥2+Ci=1∑Nξiyi(w⋅xi+b)≥1−ξi,i=1,2,⋯,Nξi≥0,i=1,2,⋯,N
等价于最优化问题
w,bmini=1∑N[1−yi(w⋅xi+b)]++λ∥w∥2
模式可分性的Cover定理
一个复杂的模式分类问题,在低维空间中非线性可分,当被非线性映射到一个足够高维的空间时,其模式线性可分的概率会显著增加。
这个定理的意义
Cover定理为核方法(Kernel Methods)提供了最根本的理论依据。
推论:在维度为m的空间中,线性可分的随机分配模式(向量)的预期最大数量等于2m。
核方法
用线性分类方法求解非线性分类问题分为两步:
- 使用变换将原空间数据映射到新空间;
- 在新空间用线性分类方法学习分类模型。
核方法属于此类方法。
核方法应用于支持向量机的基本思想:通过非线性变换将输入空间(欧氏空间 Rn 或离散集合)映射到特征空间(希尔伯特空间 H),使得输入空间 Rn 中的超曲面模型对应特征空间 H 中的超平面模型(支持向量机)。这样,分类任务通过在特征空间求解线性支持向量机即可完成。
核函数
设 X 是输入空间(欧氏空间 Rn 的子集或离散集合),又设 H 为特征空间(希尔伯特空间),如果存在一个从 X 到 H 的映射
ϕ(x):X→H
使得对所有 x,z∈X,函数 K(x,z) 满足条件
K(x,z)=ϕ(x)⋅ϕ(z)
则称 K(x,z) 为核函数,ϕ(x) 为映射函数,式中 ϕ(x)⋅ϕ(z) 为 ϕ(x) 和 ϕ(z) 的内积。
例题#1:核函数与映射函数
设输入空间 X=R2(二维欧氏空间),并定义核函数 K(x,z)=(x⋅z)2,其中 x=(x1,x2)、z=(z1,z2) 是输入空间中的向量,且 x⋅z=x1z1+x2z2 是欧氏内积。
(a) 找到一个映射函数 ϕ:R2→R3(即从二维空间到三维特征空间的映射),使得对所有 x,z∈X,有 K(x,z)=ϕ(x)⋅ϕ(z)。
(b) 给定具体点 x=(1,2) 和 z=(3,4),计算核函数值 K(x,z)。
© 使用 (a) 中定义的映射 ϕ,计算 ϕ(x) 和 ϕ(z),然后计算它们的内积 ϕ(x)⋅ϕ(z),并验证该值等于 (b) 中计算的 K(x,z).
参考答案与解析
(a)要满足 K(x,z)=(x⋅z)2=ϕ(x)⋅ϕ(z),展开左边:
(x⋅z)2=(x1z1+x2z2)2=x12z12+2x1x2z1z2+x22z22.
这可以视为一个二次型。我们希望将其表示为 ϕ(x)⋅ϕ(z),即 ϕ(x) 和 ϕ(z) 的点积。通过比较,可定义:
ϕ(x)=(x12,2x1x2,x22).
验证:
ϕ(x)⋅ϕ(z)=(x12)(z12)+(2x1x2)(2z1z2)+(x22)(z22)=x12z12+2x1x2z1z2+x22z22=(x1z1+x2z2)2=K(x,z).
因此,映射函数为 ϕ(x)=(x12,2x1x2,x22),特征空间 H=R3(标准内积)。
(b)
x⋅z=11.
K(x,z)=(x⋅z)2=112=121.
©
ϕ(x)=(x12,2x1x2,x22)=(12,2⋅1⋅2,22)=(1,22,4).
ϕ(z)=(z12,2z1z2,z22)=(32,2⋅3⋅4,42)=(9,122,16).
ϕ(x)⋅ϕ(z)=121.
正定核
已知映射函数 ϕ,可通过 ϕ(x) 和 ϕ(z) 的内积求得核函数 K(x,z)。能否不构造映射 ϕ(x) 直接判断函数 K(x,z) 是否为核函数?即 K(x,z) 需满足什么条件才能成为核函数?本节将叙述正定核的充要条件。通常所称的核函数即正定核函数(Positive Definite Kernel Function)。
正定核的充要条件
设 K:X×X→R 是对称函数,则 K(x,z) 为正定核函数的充要条件为:对任意 xi∈X(i=1,2,⋯,m),K(x,z) 对应的 Gram 矩阵
K=[K(xi,xj)]m×m
是半正定矩阵。
正定核的等价定义
设 X⊂Rn,K(x,z) 是定义在 X×X 上的对称函数。若对任意 xi∈X(i=1,2,⋯,m),K(x,z) 对应的 Gram 矩阵
K=[K(xi,xj)]m×m
是半正定矩阵,则称 K(x,z) 是正定核。
例题#2:正定核
设 X=R2,定义对称函数 K(x,z)=(x⊤z)2,其中 x,z∈R2。验证 K(x,z) 是否为正定核函数。
参考答案与解析
根据正定核的充要条件,只需验证对任意 m 个点 x1,x2,…,xm∈R2,Gram 矩阵 K=[K(xi,xj)]m×m 是半正定的。
对于 x=(x1,x2)⊤ 和 z=(z1,z2)⊤,有:
K(x,z)=(x⊤z)2=(x1z1+x2z2)2=x12z12+2x1x2z1z2+x22z22.
可以将其表示为特征映射的内积:
K(x,z)=ϕ(x)⊤ϕ(z),其中ϕ(x)=x122x1x2x22.
任取 m 个点 x(1),x(2),…,x(m)∈R2,Gram 矩阵 K 的元素为:
Kij=K(x(i),x(j))=ϕ(x(i))⊤ϕ(x(j)).
对于任意向量 c=(c1,c2,…,cm)⊤∈Rm,有:
c⊤Kc=i=1∑mj=1∑mcicjKij=i=1∑mj=1∑mcicjϕ(x(i))⊤ϕ(x(j))=i=1∑mciϕ(x(i))2≥0.
因此,K 是半正定矩阵。
常用核函数
线性核
线性核(Linear Kernel)是最简单、计算效率最高的核函数。它直接在原始输入空间中计算两个向量的点积,相当于没有使用核技巧或使用了恒等映射。其数学形式为:
K(x,z)=xTz
有时会添加一个可选的常数项 c 作为偏置:
K(x,z)=xTz+c
多项式核
多项式核(Polynomial Kernel)能够将数据映射到更高维的特征空间,学习原始空间中的多项式决策边界。其数学形式为:
K(x,z)=(γ⋅xTz+c)d
其中,由用户指定的参数 d 代表多项式的阶数,它决定了映射后特征空间的维度以及决策边界的复杂度,d 越大通常意味着模型越复杂且越可能过拟合;参数 γ 为缩放系数;而参数 c 则是一个常数项。
径向基函数
径向基函数(Radial Basis Function,RBF)是核方法中常用的一类核函数,其特点是仅依赖于输入向量间的欧氏距离的单调函数。其数学形式为:
K(x,z)=φ(∥x−z∥)
其中,∥x−z∥ 表示 x 和 z 之间的欧氏距离,φ(⋅) 是非负的单调函数。
高斯核(Gaussian RBF Kernel)形式为:
K(x,z)=exp(−2σ2∥x−z∥2)
非线性支持向量分类机
从非线性分类训练集,通过核函数与软间隔最大化或凸二次规划 (16) 学习得到的分类决策函数
f(x)=sign(i=1∑Nαi∗yiK(x,xi)+b∗)
称为非线性支持向量机,其中 K(x,z) 是正定核函数。
\begin{algorithm}
\caption{非线性支持向量机}
\begin{algorithmic}
\STATE \textbf{输入:} 训练数据集 $T = \{(x_1, y_1), (x_2, y_2), \cdots, (x_N, y_N)\}$,其中 $x_i \in \mathcal{X} = \mathbb{R}^n$,$y_i \in \mathcal{Y} = \{-1, +1\}$,$i = 1, 2, \cdots, N$
\STATE \textbf{输出:} 分类决策函数
\STATE \textbf{步骤1:构造并求解优化问题}
\STATE 选取核函数 $K(x, z)$ 和正则化参数 $C$
\STATE 求解以下凸二次规划问题:\\
$\min_{\alpha} \quad \dfrac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_i \alpha_j y_i y_j K(x_i, x_j) - \sum_{i=1}^{N} \alpha_i$ \\
$\text{s.t. } \quad \sum_{i=1}^{N} \alpha_i y_i = 0$,$0 \leq \alpha_i \leq C$,$i = 1, 2, \cdots, N$ \\
求得最优解 $\alpha^* = (\alpha_1^*, \alpha_2^*, \cdots, \alpha_N^*)^{\top}$
\STATE \textbf{步骤2:计算偏置项 $b^*$}
\STATE 选择满足 $0 < \alpha_j^* < C$ 的分量 $\alpha_j^*$
\STATE 计算:$b^* = y_j - \sum_{i=1}^{N} \alpha_i^* y_i K(x_i, x_j)$
\STATE \textbf{步骤3:构造决策函数}
\STATE 分类决策函数:$f(x) = \mathrm{sign} \left( \sum_{i=1}^{N} \alpha_i^* y_i K(x, x_i) + b^* \right)$
\STATE \textbf{返回} 分类决策函数 $f(x)$
\end{algorithmic}
\end{algorithm}
序列最小最优化算法
支持向量机原理(四)SMO算法原理 - 刘建平Pinard - 博客园
