聚类(Cluster Analysis or Clustering )是一种无监督的机器学习算法,可根据相似性或距离将不同的对象、数据点或观察结果组织和分类为不同的簇(Cluster )或类。聚类的目的是通过得到的类或簇来发现数据的特点或对数据进行处理。
聚类的相关概念
相似度或距离
聚类的核心概念是相似度或距离,有多种相似度或距离的定义。
闵可夫斯基距离
给定样本集合 X X X X X X m m m R m R^m R m x i , x j ∈ X x_i, x_j \in X x i , x j ∈ X x i = ( x 1 i , x 2 i , ⋯ , x m i ) T x_i = (x_{1i}, x_{2i}, \cdots, x_{mi})^T x i = ( x 1 i , x 2 i , ⋯ , x mi ) T x j = ( x 1 j , x 2 j , ⋯ , x m j ) T x_j = (x_{1j}, x_{2j}, \cdots, x_{mj})^T x j = ( x 1 j , x 2 j , ⋯ , x mj ) T x i x_i x i x j x_j x j Minkowski Distance )定义为
d i j = ( ∑ k = 1 m ∣ x k i − x k j ∣ p ) 1 p \begin{align}
d_{ij} = \left( \sum_{k=1}^m |x_{ki} - x_{kj}|^p \right)^{\frac{1}{p}}
\end{align}
d ij = ( k = 1 ∑ m ∣ x ki − x kj ∣ p ) p 1
这里 p ≥ 1 p \geq 1 p ≥ 1 p = 2 p = 2 p = 2 Euclidean Distance ),即
d i j = ( ∑ k = 1 m ∣ x k i − x k j ∣ 2 ) 1 2 d_{ij} = \left( \sum_{k=1}^m |x_{ki} - x_{kj}|^2 \right)^{\frac{1}{2}}
d ij = ( k = 1 ∑ m ∣ x ki − x kj ∣ 2 ) 2 1
当 p = 1 p = 1 p = 1 Manhattan Distance ),即
d i j = ∑ k = 1 m ∣ x k i − x k j ∣ d_{ij} = \sum_{k=1}^m |x_{ki} - x_{kj}|
d ij = k = 1 ∑ m ∣ x ki − x kj ∣
当 p = ∞ p = \infty p = ∞ Chebyshev Distance ),取各个坐标数值差的绝对值的最大值,即
d i j = max k ∣ x k i − x k j ∣ d_{ij} = \max_k |x_{ki} - x_{kj}|
d ij = k max ∣ x ki − x kj ∣
马哈拉诺比斯距离
马哈拉诺比斯距离(Mahalanobis Distance )简称马氏距离,也是另一种常用的相似度,考虑各个分量(特征)之间的相关性并与各个分量的尺度无关。马哈拉诺比斯距离越大,相似度越小;距离越小,相似度越大。X X X X = [ x i j ] m × n X = [x_{ij}]_{m \times n} X = [ x ij ] m × n S S S x i x_i x i x j x_j x j d i j d_{ij} d ij
d i j = [ ( x i − x j ) T S − 1 ( x i − x j ) ] 1 2 \begin{align}
d_{ij} = \left[ (x_i - x_j)^T S^{-1} (x_i - x_j) \right]^{\frac{1}{2}}
\end{align}
d ij = [ ( x i − x j ) T S − 1 ( x i − x j ) ] 2 1
其中,x i = ( x 11 , x 21 , ⋯ , x m 1 ) T , x j = ( x 1 j , x 2 j , ⋯ , x m j ) T x_i = (x_{11}, x_{21}, \cdots, x_{m1})^T, \quad x_j = (x_{1j}, x_{2j}, \cdots, x_{mj})^T x i = ( x 11 , x 21 , ⋯ , x m 1 ) T , x j = ( x 1 j , x 2 j , ⋯ , x mj ) T
相关系数
样本之间的相似度也可以用相关系数(Correlation Coefficient )来表示。相关系数的绝对值越接近 1,表示样本越相似;越接近 0,表示样本越不相似。x i x_i x i x j x_j x j
r i j = ∑ k = 1 m ( x k i − x ˉ i ) ( x k j − x ˉ j ) [ ∑ k = 1 m ( x k i − x ˉ i ) 2 ∑ k = 1 m ( x k j − x ˉ j ) 2 ] 1 2 \begin{align}
r_{ij} = \frac{\sum_{k=1}^{m}(x_{ki} - \bar{x}_i)(x_{kj} - \bar{x}_j)}{\left[\sum_{k=1}^{m}(x_{ki} - \bar{x}_i)^2\sum_{k=1}^{m}(x_{kj} - \bar{x}_j)^2\right]^{\frac{1}{2}}}
\end{align}
r ij = [ ∑ k = 1 m ( x ki − x ˉ i ) 2 ∑ k = 1 m ( x kj − x ˉ j ) 2 ] 2 1 ∑ k = 1 m ( x ki − x ˉ i ) ( x kj − x ˉ j )
其中,x ˉ i = 1 m ∑ k = 1 m x k i , x ˉ j = 1 m ∑ k = 1 m x k j \bar{x}_i = \frac{1}{m}\sum_{k=1}^{m}x_{ki}, \quad \bar{x}_j = \frac{1}{m}\sum_{k=1}^{m}x_{kj} x ˉ i = m 1 ∑ k = 1 m x ki , x ˉ j = m 1 ∑ k = 1 m x kj
夹角余弦
样本之间的相似度也可以用夹角余弦来表示。夹角余弦越接近 1,表示样本越相似;越接近 0,表示样本越不相似。x i x_i x i x j x_j x j
s i j = ∑ k = 1 m x k i x k j ( ∑ k = 1 m x k i 2 ∑ k = 1 m x k j 2 ) 1 2 \begin{align}
s_{ij} = \frac{\sum_{k=1}^{m}x_{ki}x_{kj}}{\left(\sum_{k=1}^{m}x_{ki}^2\sum_{k=1}^{m}x_{kj}^2\right)^{\frac{1}{2}}}
\end{align}
s ij = ( ∑ k = 1 m x ki 2 ∑ k = 1 m x kj 2 ) 2 1 ∑ k = 1 m x ki x kj
类或簇
通过聚类得到的类或族本质是样本的子集。如果一个聚类方法假定一个样本只能属于一个类或类的交集为空集,那么该方法称为硬聚类 方法。否则,如果一个样本可以属于多个类或类的交集不为空集,那么该方法称为软聚类 方法。本章只考虑硬聚类方法。G G G x i , x j x_i, x_j x i , x j n G n_G n G G G G d i j d_{ij} d ij x i x_i x i x j x_j x j T T T G G G x i , x j x_i, x_j x i , x j
d i j ≤ T \begin{align}
d_{ij} \leq T
\end{align}
d ij ≤ T
则称 G G G x ˉ G \bar{x}_G x ˉ G x ˉ G \bar{x}_G x ˉ G
x ˉ G = 1 n G ∑ i = 1 n G x i \begin{align}
\bar{x}_G = \frac{1}{n_G} \sum_{i=1}^{n_G} x_i
\end{align}
x ˉ G = n G 1 i = 1 ∑ n G x i
式中 n G n_G n G G G G D G D_G D G D G D_G D G
D G = max x i , x j ∈ G d i j \begin{align}
D_G = \max_{x_i, x_j \in G} d_{ij}
\end{align}
D G = x i , x j ∈ G max d ij
(3) 类的样本散布矩阵 A G A_G A G S G S_G S G A G A_G A G
A G = ∑ i = 1 n G ( x i − x ˉ G ) ( x i − x ˉ G ) T \begin{align}
A_G = \sum_{i=1}^{n_G} (x_i - \bar{x}_G)(x_i - \bar{x}_G)^T
\end{align}
A G = i = 1 ∑ n G ( x i − x ˉ G ) ( x i − x ˉ G ) T
样本协方差矩阵 S G S_G S G
S G = 1 n G − 1 A G = 1 n G − 1 ∑ i = 1 n G ( x i − x ˉ G ) ( x i − x ˉ G ) T \begin{align}
S_G = \frac{1}{n_G - 1} A_G = \frac{1}{n_G - 1} \sum_{i=1}^{n_G} (x_i - \bar{x}_G)(x_i - \bar{x}_G)^T
\end{align}
S G = n G − 1 1 A G = n G − 1 1 i = 1 ∑ n G ( x i − x ˉ G ) ( x i − x ˉ G ) T
类与类之间的距离
下面考虑类 G p G_p G p G q G_q G q D ( p , q ) D(p, q) D ( p , q ) 连接 (Linkage )。类与类之间的距离也有多种定义。G p G_p G p n p n_p n p G q G_q G q n q n_q n q x ˉ p \bar{x}_p x ˉ p x ˉ q \bar{x}_q x ˉ q G p G_p G p G q G_q G q Single Linkage )G p G_p G p G q G_q G q
D p q = min { d i j ∣ x i ∈ G p , x j ∈ G q } \begin{align}
D_{pq} = \min \{ d_{ij} \mid x_i \in G_p, x_j \in G_q \}
\end{align}
D pq = min { d ij ∣ x i ∈ G p , x j ∈ G q }
(2) 最长距离或完全连接(Complete Linkage )G p G_p G p G q G_q G q
D p q = max { d i j ∣ x i ∈ G p , x j ∈ G q } \begin{align}
D_{pq} = \max \{ d_{ij} \mid x_i \in G_p, x_j \in G_q \}
\end{align}
D pq = max { d ij ∣ x i ∈ G p , x j ∈ G q }
(3) 中心距离G p G_p G p G q G_q G q x ˉ p \bar{x}_p x ˉ p x ˉ q \bar{x}_q x ˉ q
D p q = d x ˉ p x ˉ q \begin{align}
D_{pq} = d_{\bar{x}_p \bar{x}_q}
\end{align}
D pq = d x ˉ p x ˉ q
这种连接在代码里面体现在合并簇时采用取平均 的方式。G p G_p G p G q G_q G q
D p q = 1 n p n q ∑ x i ∈ G p ∑ x j ∈ G q d i j \begin{align}
D_{pq} = \frac{1}{n_p n_q} \sum_{x_i \in G_p} \sum_{x_j \in G_q} d_{ij}
\end{align}
D pq = n p n q 1 x i ∈ G p ∑ x j ∈ G q ∑ d ij
层次聚类
层次聚类假设类别之间存在层次结构,将样本聚到层次化的类中。层次聚类有:
聚合式或自下而上的方法,这种方法反复将聚类合并成更大的聚类,直到形成一个单个聚类;
分割式或自上而下的方法,这种方法从单个聚类中的所有数据开始,然后继续拆分连续的聚类,直到所有的聚类都是单一聚类。
\begin{algorithm}
\caption{层次聚类}
\begin{algorithmic}
\REQUIRE 样本集合 $X = \{ x_1, x_2, \cdots, x_n \}$,其中 $x_i \in \mathbb{R}^m$;样本间距离度量
\ENSURE 样本集合的层次化聚类结构
\STATE 计算所有样本两两之间的欧氏距离:$d_{ij} = \| x_i - x_j \|_2$,构建距离矩阵 $D = [d_{ij}]_{n \times n}$
\STATE 创建 $n$ 个初始类:$C_i = \{x_i\}, \quad i = 1, 2, \cdots, n$
\WHILE{类的个数 > 1}
\STATE 找到距离最小的两个类:$(C_p, C_q) = \arg\min_{i < j} d(C_i, C_j)$
\STATE 合并这两个类,形成新类:$C_{\text{new}} = C_p \cup C_q$
\STATE 从当前类集合中移除 $C_p$ 和 $C_q$,加入 $C_{\text{new}}$
\STATE 更新距离矩阵:计算 $C_{\text{new}}$ 与其余各类的距离(使用最短距离/单链法)
\ENDWHILE
\STATE \textbf{返回} 样本集合的层次化聚类
\end{algorithmic}
\end{algorithm}
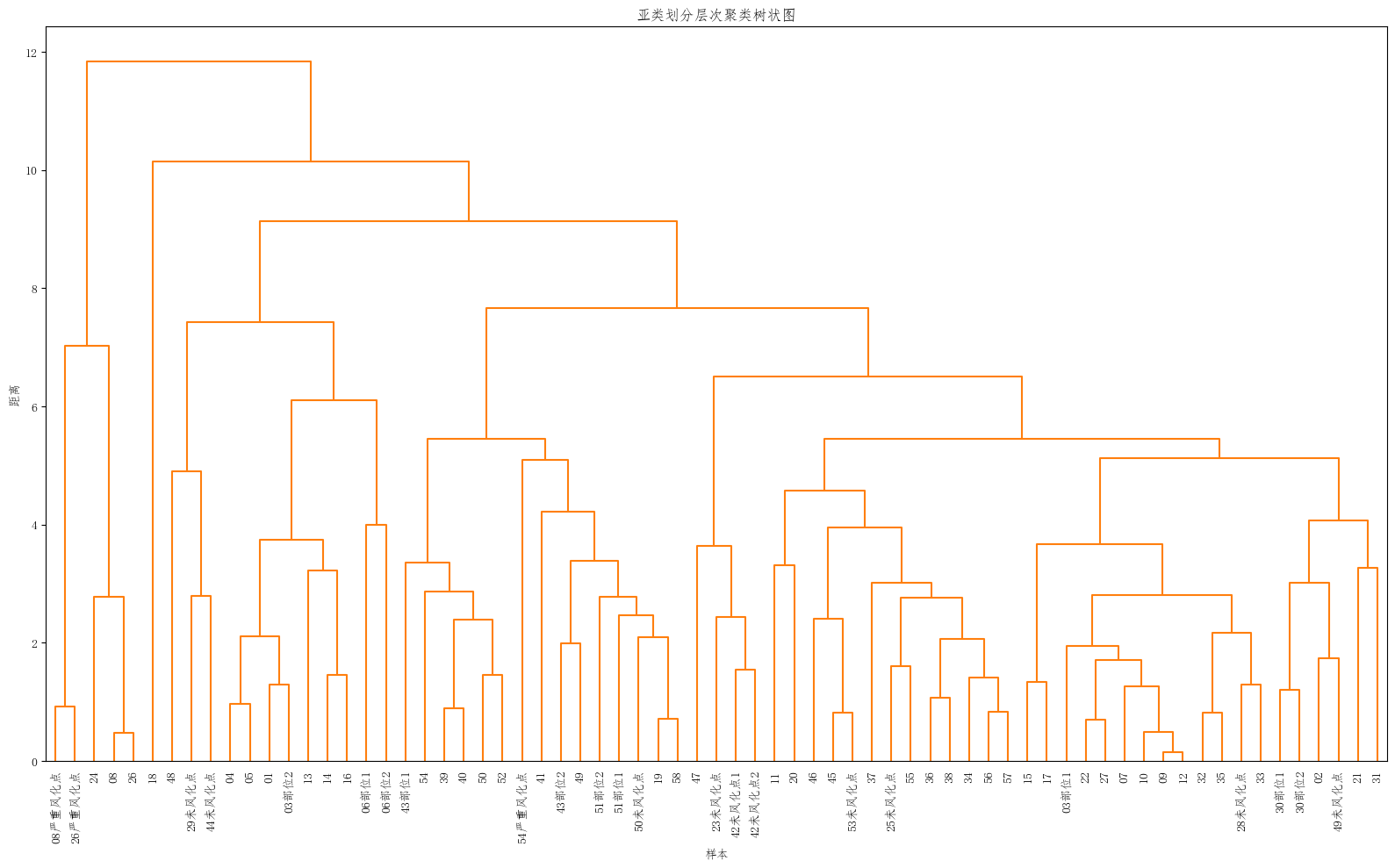
聚类方法实战#1:2022高教社杯全国大学生数学建模竞赛C题 古代玻璃制品的成分分析与鉴别
针对问题2:依据附件数据分析高钾玻璃、铅钡玻璃的分类规律;对于每个类别选择合适的化学成分对其进行亚类划分,给出具体的划分方法及划分结果,并对分类结果的合理性和敏感性进行分析。此题选用层次聚类方法进行亚类划分是合理的,因其天然具备的层次结构能满足亚类划分的需求。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.preprocessing import StandardScalerfrom scipy.cluster.hierarchy import dendrogram, linkageplt.rcParams['font.sans-serif' ] = ['FangSong' ] file_path = 'C:\\...\\附件.xlsx' sheet2 = pd.read_excel(file_path, sheet_name='表单2' , header=0 ) data = sheet2.set_index(sheet2.columns[0 ]) data = data.fillna(0 ) scaler = StandardScaler() scaled_data = scaler.fit_transform(data) Z = linkage(scaled_data, method='complete' ) plt.figure(figsize=(16 , 10 )) dendrogram(Z, labels=data.index.tolist(), orientation='top' , leaf_rotation=90 , leaf_font_size=10 , color_threshold=25 ) plt.title('亚类划分层次聚类树状图' ) plt.xlabel('样本' ) plt.ylabel('距离' ) plt.tight_layout() plt.show()
其中Z Z Z ( n − 1 ) × 4 (n - 1) \times 4 ( n − 1 ) × 4 Z \mathbf{Z} Z i i i Z [ i , 0 ] \mathbf{Z}[i, 0] Z [ i , 0 ] Z [ i , 1 ] \mathbf{Z}[i, 1] Z [ i , 1 ] n + i n + i n + i n n n n n n Z [ i , 0 ] \mathbf{Z}[i, 0] Z [ i , 0 ] Z [ i , 1 ] \mathbf{Z}[i, 1] Z [ i , 1 ] Z [ i , 2 ] \mathbf{Z}[i, 2] Z [ i , 2 ] Z [ i , 3 ] \mathbf{Z}[i, 3] Z [ i , 3 ]
聚类 n + i 聚类 j 聚类 k 两个类的距离 聚类 n + i 中包含的原始观测点数量 聚类n+i \quad \boxed{聚类j \quad 聚类k \quad 两个类的距离 \quad 聚类n+i中包含的原始观测点数量}
聚类 n + i 聚类 j 聚类 k 两个类的距离 聚类 n + i 中包含的原始观测点数量
得出来的结果如下:
k均值聚类
k k k k k k 基于中心点的迭代式 聚类算法,该算法通过计算聚类中心之间的距离,将数据集划分为若干相似组。聚类中心(即簇中心点)的计算方式可根据数据特性选择:既可采用簇内所有数据点的均值,亦可采用其中位数。k k k 从样本到类的函数 。
\begin{algorithm}
\caption{$k$-means Clustering}
\begin{algorithmic}
\REQUIRE 集合 $\boldsymbol{X}$,包含 $n$ 个样本
\ENSURE 聚类结果 $C^*$
\STATE 初始化:设迭代次数 $t = 0$,随机选择 $k$ 个样本作为初始类中心 $m^{(0)} = \left( m_1^{(0)}, m_2^{(0)}, \cdots, m_k^{(0)} \right)$
\REPEAT
\STATE \textbf{样本聚类}:对当前中心 $m^{(t)} = \left( m_1^{(t)}, \cdots, m_k^{(t)} \right)$,其中 $m_l^{(t)}$ 为类 $G_l$ 的中心。计算每个样本到各类中心的距离,将样本分配到最近的类,形成聚类结果 $C^{(t)} = \{ G_1, \cdots, G_k \}$。
\STATE \textbf{更新类中心}:对聚类结果 $C^{(t)}$,计算各类中样本的均值,作为新的类中心$m^{(t+1)} = \left( m_1^{(t+1)}, m_2^{(t+1)}, \cdots, m_k^{(t+1)} \right)$
\STATE $t \gets t + 1$
\UNTIL{满足收敛条件或停止准则}
\STATE \textbf{输出}:$C^* = C^{(t)}$
\end{algorithmic}
\end{algorithm}
类别数k k k
k k k k k k k k k k k k Elbow Method )。其原理是计算各数据点与其聚类中心的欧氏距离,并通过观察簇内平方和(Within Cluster Sum of Squares ,WCSS )的变化拐点确定聚类数。具体而言:将WCSS值聚类数量绘制曲线,选择方差变化趋于平缓的转折点作为最优解。
聚类方法实战#2:爱荷华州埃姆斯市房屋的聚类分析
网址:Clustering With K-Means Exercise: Clustering With K-Means|Kaggle Notebook Editor