
DL#3 卷积神经网络
不错的学习资源:CS 230 - Convolutional Neural Networks Cheatsheet
卷积神经网络(Convolutional Neural Network,CNN)是一类包含卷积计算,对图像数据(更一般地格点数据)进行预测的具有深度结构的前馈神经网络。
从信号与系统的卷积开始
在信号与系统中,卷积是描述线性时不变(LTI)系统输入输出关系的关键运算。
其中叫做核函数。
离散情况下
在信号与系统的传统语境中,卷积输出 通常被称为系统响应或滤波后的信号。然而,当卷积运算被用于特征提取(尤其是在图像处理、模式识别和深度学习中)时,输出 或离散情况下的 就常被称为特征映射。
卷积操作本质上是将输入信号 映射到一个新的表示空间,突出或提取输入中与核函数相关的特定特征。核函数 定义了系统关注的特性,如频率响应、边缘或模式。卷积过程通过滑动 与 进行局部加权积分,计算每个时刻 输入信号与核的相似度。输出 因此形成一种映射,其中高值区域对应于输入信号中核函数所代表的特征被显著激活的区域。文章为什么学了信号与系统后感觉只会作些课后题,对它的原理和本质很迷茫? - 知乎说的更专业一些(当然英文词汇也更多,要求有一定的泛函分析的知识储量)。
在机器学习、深度学习中,卷积实际上是用互相关函数实现的。
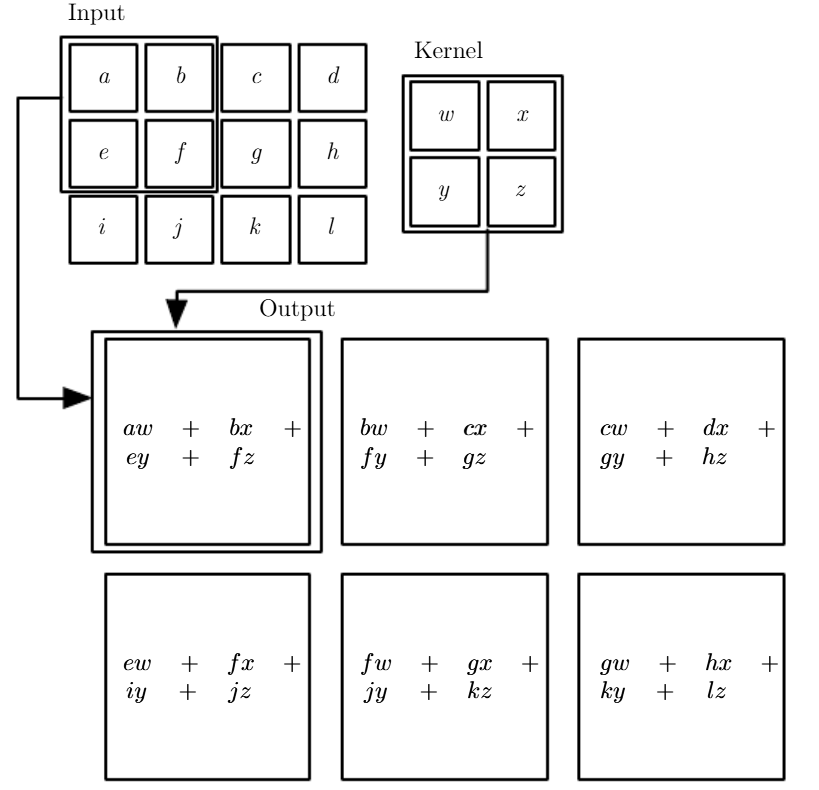
卷积运算通过三个重要的思想来帮助改进机器学习系统: 稀疏交互(Sparse Interactions)、 参数共享(Parameter Sharing)、 等变表示(Equivariant Representations)。
卷积网络具有稀疏交互(也叫做稀疏连接或者稀疏权重)的特征。这是使核的大小远小于输入的大小来达到的。稀疏交互的物理意义是,通常图像、文本、语音等现实世界中的数据都具有局部的特征结构,我们可以先学习局部的特征,再将局部的特征组合起来形成更复杂和抽象的特征。
参数共享是指在一个模型的多个函数中使用相同的参数。 在传统的神经网络中,当计算一层的输出时,权重矩阵的每一个元素只使用一次,当它乘以输入的一个元素后就再也不会用到了。在卷积神经网络中,核的每一个元素都作用在输入的每一位置上(是否考虑边界像素取决于对边界决策的设计)。卷积运算中的参数共享保证了我们只需要学习一个参数集合,而不是对于每一位置都需要学习一个单独的参数集合。参数共享的物理意义是使得卷积层具有平移等变性。假如图像中有一只猫, 那么无论它出现在图像中的任何位置,我们都应该将它识别为猫,也就是说神经网络的输出对于平移变换来说应当是等变的。
卷积神经网络通过特殊的函数表示和学习实现了自己的感受野(Receptive Field)机制。在卷积神经网络中,感受野是指特征图上的某个点能看到的输入图像的区域,即特征图上的点是由输入图像中感受野大小区域的计算得到的。
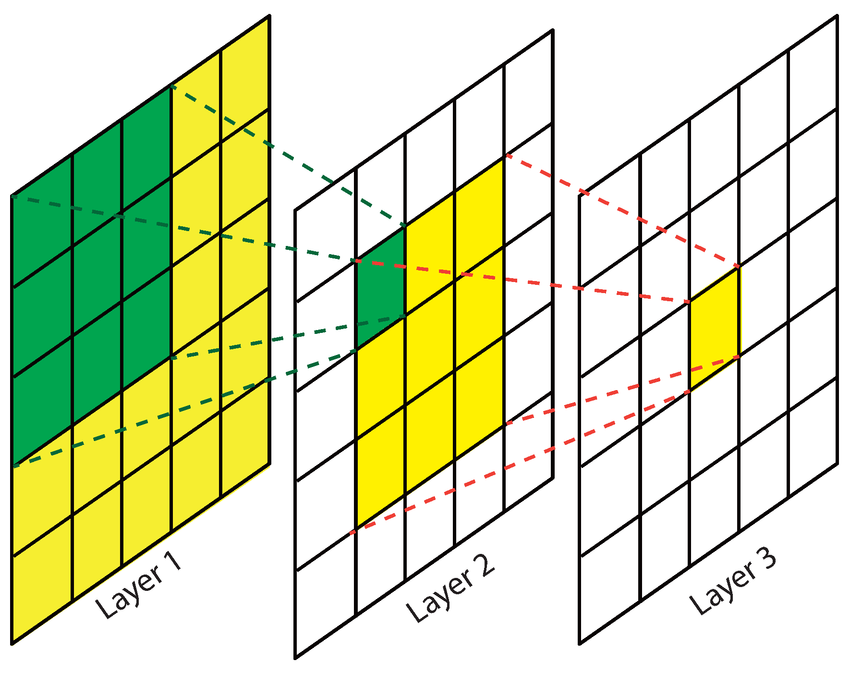
卷积运算的扩展可以通过增加填充和步幅实现。在输入矩阵的周边添加元素为 的行和列,使卷积核能更充分地作用于输入矩阵边缘的元素,这样的处理称为填充 (Padding) 或零填充。
池化
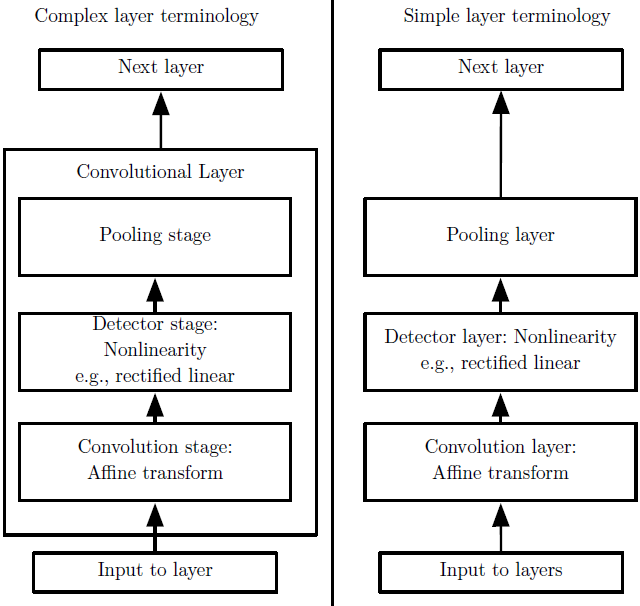
卷积网络中一个典型层包含三级。在第一级中,这一层并行地计算多个卷积产生一组线性激活响应。在第二级中,每一个线性激活响应将会通过一个非线性的激活函数,例如整流线性激活函数。这一级有时也被称为探测级(Detector Stage)。在第三级中,我们使用池化(或称汇聚,Pooling)函数来进一步调整这一层的输出。池化依赖于核的大小、填充的大小和步幅,也就是说,这些都是超参数。
给定一个 输入矩阵 ,一个虚设的 核矩阵,。让核矩阵在输入矩阵上从左到右再从上到下滑动,将输入矩阵划分成若干大小为 的子矩阵。这些子矩阵相互不重叠且完全覆盖整个输入矩阵。对每一个子矩阵求最大值或平均值,产生一个 输出矩阵 ,称此运算为汇聚或二维汇聚。对于矩阵取最大值的称为最大汇聚。取平均值的称为平均汇聚。即有
或
其中,, 和 满足
这里假设 和 分别可以被 和 整除。

不管采用什么样的池化函数,当输入作出少量平移时,池化能够帮助输入的表示近似不变。局部平移不变性是一个很有用的性质,尤其是当我们关心某个特征是否出现而不关心它出现的具体位置时。因为池化综合了全部邻居的反馈,这使得池化单元少于探测单元成为可能,我们可以通过综合池化区域的 个像素的统计特征而不是单个像素来实现。
多输入多输出通道
当我们添加通道时,我们的输入和隐藏的表示都变成了三维张量。例如,每个RGB输入图像具有的形状。我们将这个大小为的轴称为通道(channel)维度。本节将更深入地研究具有多输入和多输出通道的卷积核。

最流行的神经网络架构中,随着神经网络层数的加深,我们常会增加输出通道的维数,通过减少空间分辨率以获得更大的通道深度。直观地说,我们可以将每个通道看作对不同特征的响应。而现实可能更为复杂一些,因为每个通道不是独立学习的,而是为了共同使用而优化的。因此,多输出通道并不仅是学习多个单通道的检测器。
用和分别表示输入和输出通道的数目,并让和为卷积核的高度和宽度。为了获得多个通道的输出,我们可以为每个输出通道创建一个形状为的卷积核张量,这样卷积核的形状是。在互相关运算中,每个输出通道先获取所有输入通道,再以对应该输出通道的卷积核计算出结果。

ResNet
ResNet论文:[1512.03385] Deep Residual Learning for Image Recognition
ResNet论文逐段精读【论文精读】_哔哩哔哩_bilibili
论文首先提出”学些更好的网络是否像堆叠更多的层一样容易?“(Is learning better networks as easy as stacking more layers?),进而发现深度网络出现了退化问题。随着层数的增加,在极端情况下这些层什么也不会学习,是恒等映射。这一现象与直觉相悖:理论上,更深的网络至少应具备不逊于其浅层子网络的性能。为解决这一难题,论文进而提出了一种创新的残差学习框架(Residual Learning Framework)。
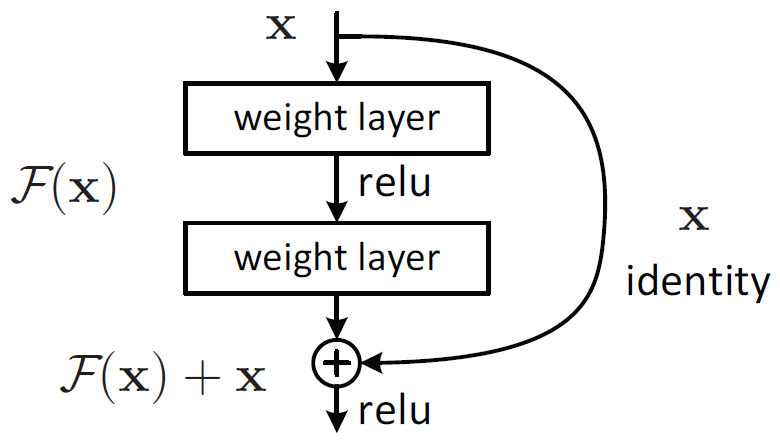
形式上,输入特征图为,期望的理想映射为。ResNet的核心思想在于显式地让网络层学习残差函数,而不直接学习 。ResNet通过引入跳跃连接(shortcut connection)构建残差块(residual block)。当残差为0时,该单元只做到恒等映射,但是实际上残差不会为0,这就使残差学习单元能学到新的特征。因此,对于残差学习单元,它实际上学习的是而非。
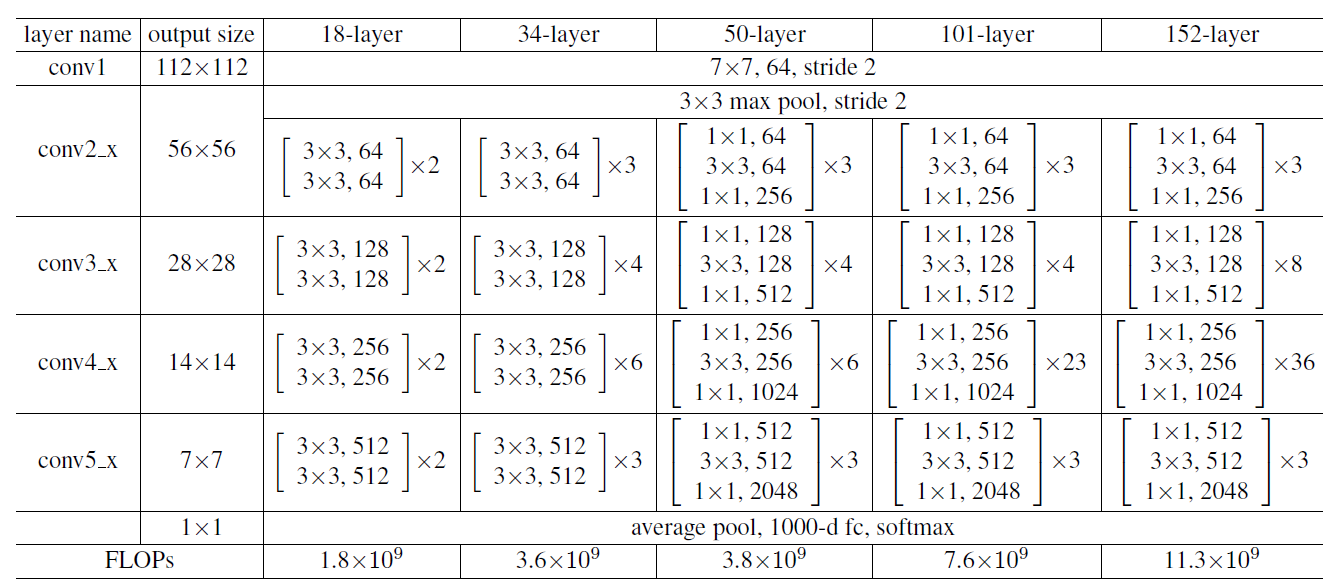
在ResNet中,投影短路(Projection Shortcuts)使用 卷积调整维度,而其他短路保持恒等映射,这是为了解决残差块输入/输出维度不一致时的计算问题。
深度学习实战#2 卷积神经网络
前情提要:DL#2 神经网络模型优化 | TheValuePoint’s Blog
其余函数不变,只需要创建一个CNN类即可。
1 | class CNN(nn.Module): |